Neural/Deep Networks
Whether to construct predictive models of user behavior or player affect, to find mappings between game elements and their aesthetics, or to figure out the goals of a human co-creator, machine learning based on neural networks is a powerful tool for realizing artificial intelligence.
InvPatch: Prefix-Based Conditional Generation for Inverse Dynamics
Nemanja Rasajski, Konstantinos Makantasis, Antonios Liapis, and Georgios N. Yannakakis
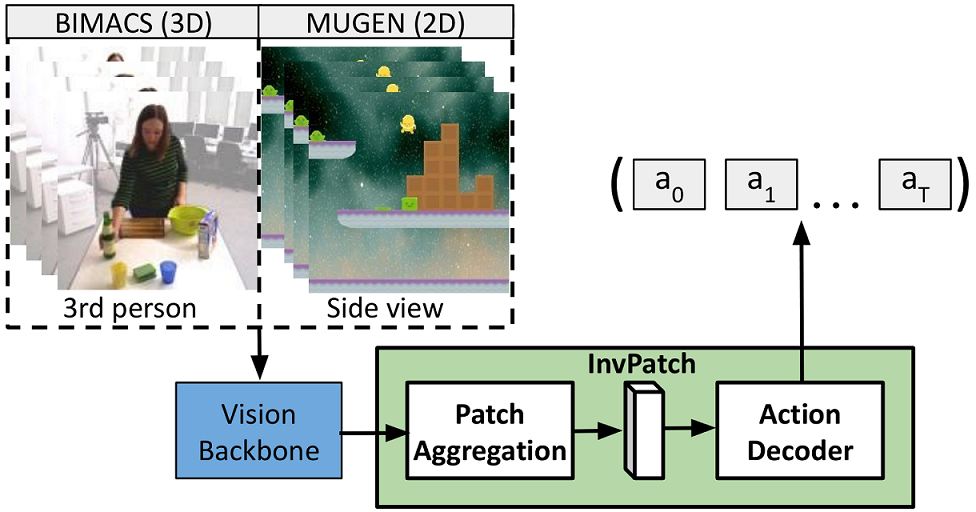
High level overview of InvPatch: we learn a global video embedding and use it to condition the action decoder to produce viable sequences of actions across several timesteps.
Abstract: Inverse Dynamics Models (IDMs) attempt to predict the actions that cause observable changes in a scene. Current methods for building accurate IDMs either rely on rule-based systems that exploit video metadata or require large-scale training over thousands of video hours. These approaches are inevitably limited to a single domain due to the difficulty of acquiring metadata or sufficient training data across different domains. In response to these challenges, this study draws inspiration from data-efficient video captioning methods, specifically prefix-based conditional generation. This approach maps visual features into prefix tokens that condition the action-prediction process. We introduce InvPatch, a framework that builds on prefix-based conditional generation and extends it by adding learned visual-representation compression. In InvPatch, attention-based patch selection and pooling are applied to features extracted from a ViT backbone, reducing the conditioning input from a set of frame-by-frame features to a single vector. We evaluate our framework across two diverse settings: 3D third-person real world (KIT Bimanual Actions) and 2D synthetic (MUGEN). Our method achieves 97.21% accuracy on MUGEN and surpasses state-of-the-art results on KIT Bimanual Actions. Our sensitivity analysis highlights the data efficiency of this approach, as InvPatch maintains comparable performance even when trained with 30% less data. Additionally, our runtime analysis demonstrates the computational efficiency of InvPatch, which requires fewer trainable parameters and performs fewer FLOPs compared to other methods.
in Proceedings of the IEEE Conference on Artificial Intelligence, 2026. BibTex
Diverse Level Generation via Machine Learning of Quality Diversity
Konstantinos Sfikas, Antonios Liapis, Georgios N. Yannakakis
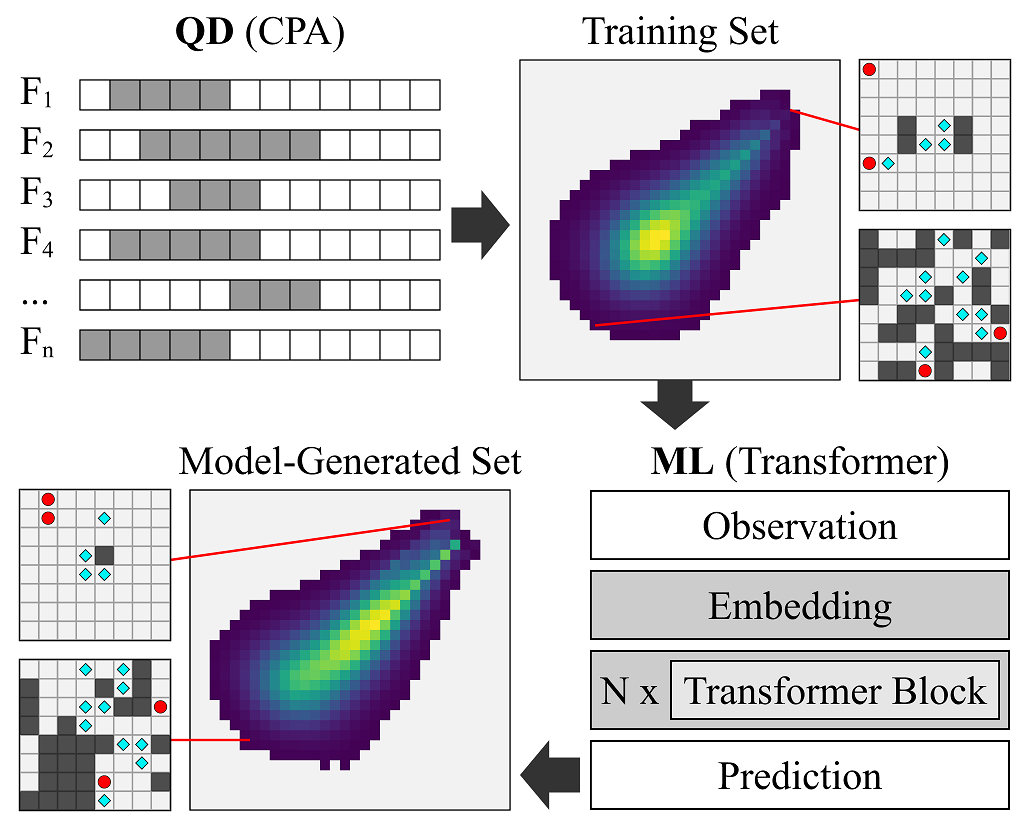
High level representation of MLQD as employed for a level generation task. A QD algorithm (FI-CPA in this example) generates a large and diverse training set of game levels. A generative model (a Transformer in this example) is trained on this set. The model's output resembles the distribution of the training set by machine learning the behavior of QD.
Abstract: Can we replicate the power of evolutionary algorithms in discovering good and diverse game content via generative machine learning (ML) techniques? This question could subvert current trends in procedural content generation (PCG) and beyond. By learning the behavior of quality-diversity (QD) evolutionary algorithms through ML, we stand to overcome the computational challenges inherent in QD search and ensure that the benefits of QD search are reproduced by efficient generative models. We introduce a novel, end-to-end methodology named Machine Learning of Quality Diversity (MLQD) which is executed in two steps. First, tailored QD evolution creates large and diverse training datasets from the ground up. Second, sophisticated ML architectures such as the Transformer learn the datasets' underlying distributions, resulting in generative models that can emulate QD search via stochastic inference. We test MLQD on the use-case of generating strategy game map sketches, a task characterized by stringent constraints and a multidimensional feature space. Our findings are promising, demonstrating that the Transformer architecture can capture both the diversity and the quality traits of the training sets, successfully reproducing the behavior of a range of tested QD algorithms. This marks a significant advancement in our quest to automate the creation of high-quality, diverse game content, pushing the boundaries of what is possible in PCG and generative AI at large.
in Proceedings of the FDG Workshop on Procedural Content Generation, 2025. BibTex
Large Language Models and Games: A Survey and Roadmap
Roberto Gallotta, Graham Todd, Marvin Zammit, Sam Earle, Antonios Liapis, Julian Togelius, Georgios N. Yannakakis
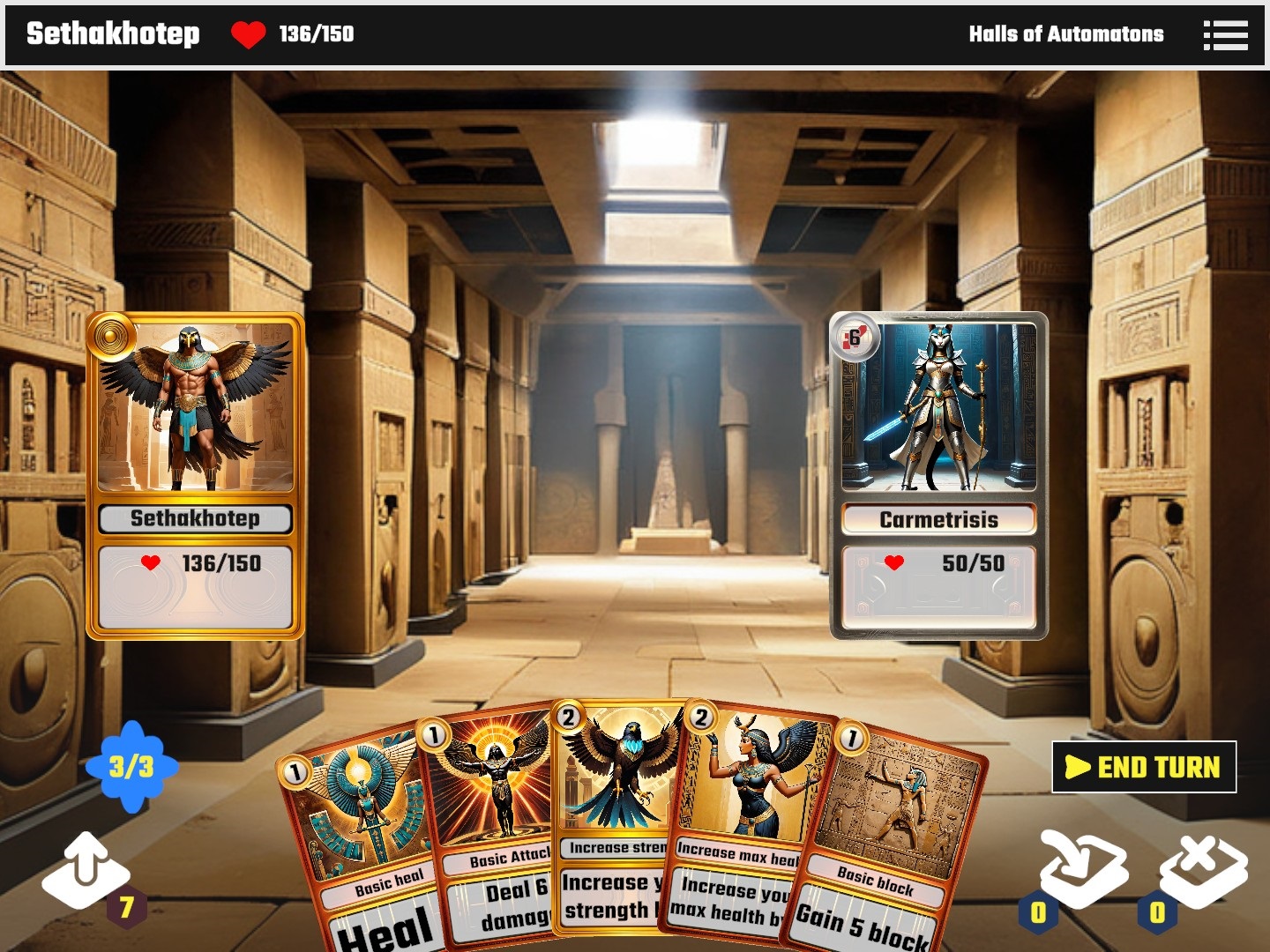
A large language model (LLM) can operate within the game as a player or as a non-player character, as a player assistant, as a Game Master, or controlling a mechanic of the game. Outside of the game's runtime, an LLM can act as a designer (replacing or assisting a human designer) or as analyst of players' data. Here, we see an example of an automated LLM designer producing card battle setups in CrawLLM.
Abstract: Recent years have seen an explosive increase in research on large language models (LLMs), and accompanying public engagement on the topic. While starting as a niche area within natural language processing, LLMs have shown remarkable potential across a broad range of applications and domains, including games. This paper surveys the current state of the art across the various applications of LLMs in and for games, and identifies the different roles LLMs can take within a game. Importantly, we discuss underexplored areas and promising directions for future uses of LLMs in games and we reconcile the potential and limitations of LLMs within the games domain. As the first comprehensive survey and roadmap at the intersection of LLMs and games, we are hopeful that this paper will serve as the basis for groundbreaking research and innovation in this exciting new field.
in IEEE Transactions on Games, 2024 (Early Access). BibTex
BehAVE: Behaviour Alignment of Video Game Encodings
Nemanja Rasajski, Chintan Trivedi, Konstantinos Makantasis, Antonios Liapis, Georgios N. Yannakakis
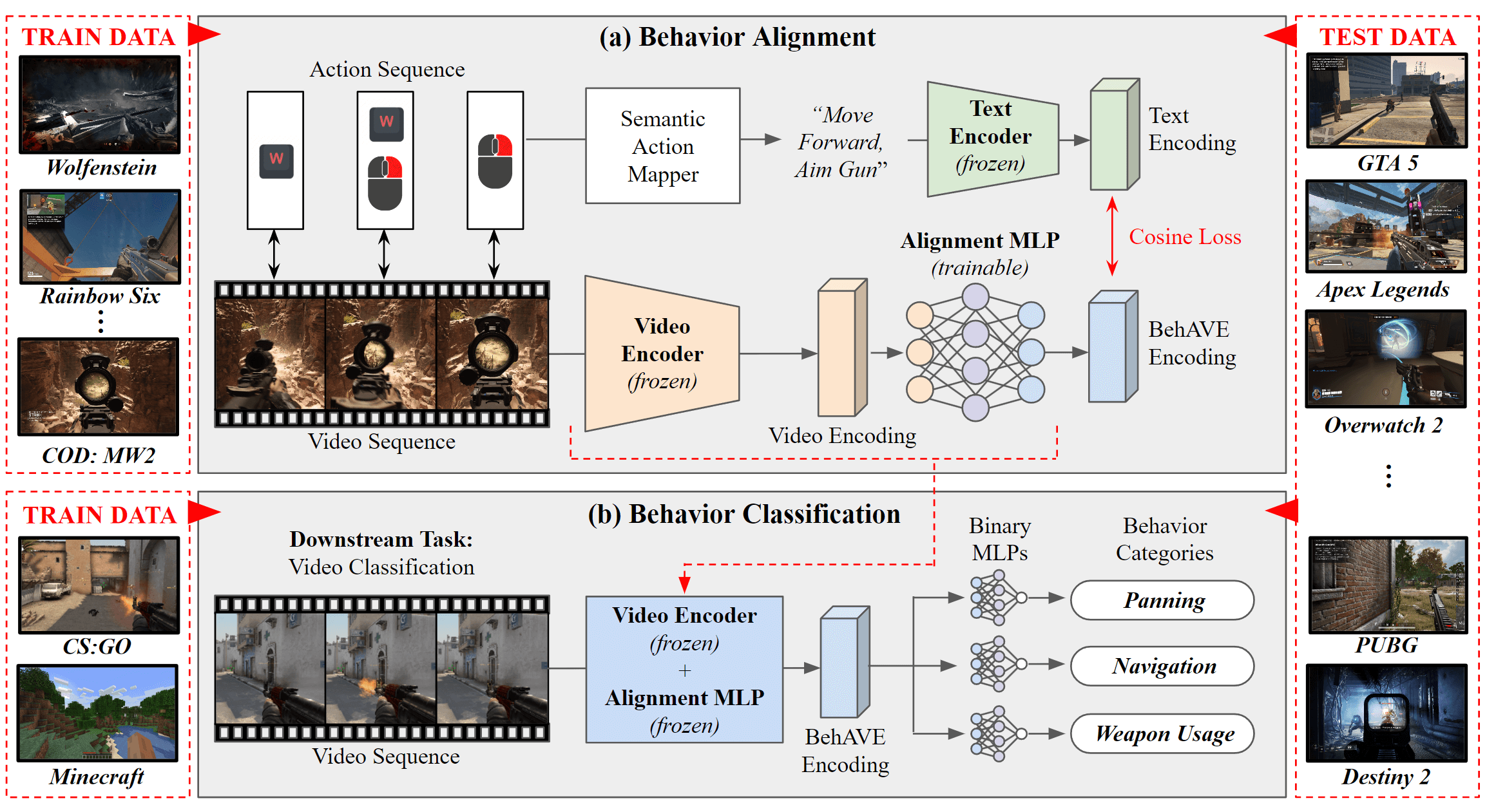
BehAVE is trained on synchronised gameplay video and player actions from the Synchronized Multi-Game FPS train dataset (top), to produce pixel-based encodings that are aligned to similar player actions across games. These encodings are tested in a video classification task (bottom) by training classifiers on CS:GO or Minecraft, and testing classification accuracies on unseen games from the Synchronized Multi-Game FPS dataset.
Abstract: Domain randomisation enhances the transferability of vision models across visually distinct domains with similar content. However, current methods heavily depend on intricate simulation engines, hampering feasibility and scalability. This paper introduces BehAVE, a video understanding framework that utilises existing commercial video games for domain randomisation without accessing their simulation engines. BehAVE taps into the visual diversity of video games for randomisation and uses textual descriptions of player actions to align videos with similar content. We evaluate BehAVE across 25 first-person shooter (FPS) games using various video and text foundation models, demonstrating its robustness in domain randomisation. BehAVE effectively aligns player behavioural patterns and achieves zero-shot transfer to multiple unseen FPS games when trained on just one game. In a more challenging scenario, BehAVE enhances the zero-shot transferability of foundation models to unseen FPS games, even when trained on a game of a different genre, with improvements of up to 22%. BehAVE is available online.
in Proceedings of the ECCV Workshop on Computer Vision For Videogames, 2024. BibTex
The Scream Stream: Multimodal Affect Analysis of Horror Game Spaces
Emmanouil Xylakis, Antonios Liapis, Georgios N. Yannakakis

One of the many jump scares of the Outlast Asylum Affect Corpus, depicting in-game visuals and face cam of YouTube user AnidaGaming. Image used with the streamer's permission.
Abstract: Virtual environments allow us to study the impact of space on the emotional patterns of a user as they navigate through it. Similarly, digital games are capable of eliciting intense emotional responses from their players; moreso when the game is explicitly designed to do this, as in the Horror game genre. A growing body of literature has already explored the relationship between varying virtual space contexts and user emotion manifestation in horror games, often relying on physiological data or self-reports. In this paper, instead, we study players' emotion manifestations within this game genre. Specifically, we analyse facial expressions, voice signals, and verbal narration of YouTube streamers while playing the Horror game Outlast. We document the collection of the Outlast Asylum Affect corpus from in-the-wild videos, and its analysis into three different affect streams based on the streamer's speech and face camera data. These affect streams are juxtaposed with manually labelled gameplay and spatial transitions during the streamer's exploration of the virtual space of the Asylum map of the Outlast game. Results in terms of linear and non-linear relationships between captured emotions and the labelled features demonstrate the importance of a gameplay context when matching affect to level design parameters. This study is the first to leverage state-of-the-art pre-trained models to derive affect from streamers' facial expressions, voice levels, and utterances and opens up exciting avenues for future applications that treat streamers' affect manifestations as in-the-wild affect corpora.
in Proceedings of the International Conference on Affective Computing and Intelligent Interaction Workshops and Demos, 2024. BibTex
Varying the Context to Advance Affect Modelling: A Study on Game Engagement Prediction
Kosmas Pinitas, Nemanja Rasajski, Matthew Barthet, Maria Kaselimi, Konstantinos Makantasis, Antonios Liapis, Georgios N. Yannakakis

The GameVibe corpus contains 2 hours of gameplay footage annotated for viewer engagement. The corpus includes footage from 30 First Person Shooter games between 1992 and 2023, with varied game modes and audiovisual styles.
Abstract: Affective computing faces a pressing challenge: the limited ability of affect models to generalise amidst varying contextual factors within the same task. While well recognised, this challenge persists due to the absence of suitable large-scale corpora with rich and diverse contextual information within a domain. To address this challenge, this paper introduces a GameVibe, a novel corpus explicitly tailored to confront the lack of contextual diversity. The affect corpus is sourced from 30 First Person Shooter (FPS) games, showcasing diverse game modes and designs within the same domain. The corpus comprises 2 hours of annotated gameplay videos with engagement levels annotated by a total of 20 participants in a time-continuous manner. Our preliminary analysis on this corpus sheds light on the complexity of generalising affect predictions across contextual variations in similar affective computing tasks. These initial findings serve as a catalyst for further research, inspiring deeper inquiries into this critical, yet understudied, aspect of affect modelling.
in Proceedings of the International Conference on Affective Computing and Intelligent Interaction, 2024. BibTex
MAP-Elites with Transverse Assessment for Multimodal Problems in Creative Domains
Marvin Zammit, Antonios Liapis, Georgios N. Yannakakis

The MEliTA process: an elite is selected from the featuremap, and one of its modalities (image) is altered. Then, this new image is mapped to another row of cells in the featuremap and new candidate solutions are produced by combining the new image and the elites' old text modality. The best combination of new image and older text survives and replaces the previous individual or occupies a new cell.
Abstract: The recent advances in language-based generative models have paved the way for the orchestration of multiple generators of different artefact types (text, image, audio, etc.) into one system. Presently, many open-source pre-trained models combine text with other modalities, thus enabling shared vector embeddings to be compared across different generators. Within this context we propose a novel approach to handle multimodal creative tasks using Quality Diversity evolution. Our contribution is a variation of the MAP-Elites algorithm, MAP-Elites with Transverse Assessment (MEliTA), which is tailored for multimodal creative tasks and leverages deep learned models that assess coherence across modalities. MEliTA decouples the artefacts' modalities and promotes cross-pollination between elites. As a test bed for this algorithm, we generate text descriptions and cover images for a hypothetical video game and assign each artefact a unique modality-specific behavioural characteristic. Results indicate that MEliTA can improve text-to-image mappings within the solution space, compared to a baseline MAP-Elites algorithm that strictly treats each image-text pair as one solution. Our approach represents a significant step forward in multimodal bottom-up orchestration and lays the groundwork for more complex systems coordinating multimodal creative agents in the future.
in Proceedings of the International Conference on Computational Intelligence in Music, Sound, Art and Design (EvoMusArt), 2024. BibTex
Towards General Game Representations: Decomposing Games Pixels into Content and Style
Chintan Trivedi, Konstantinos Makantasis, Antonios Liapis, Georgios N. Yannakakis
The proposed framework uses multiple games from the same genre to transform latent representations to two lower-dimensional embeddings: one for content and one for style. The t-SNE plot visualizes the domain gap in the latent representations and shows how these differences are flattened into a separate style subspace which filters out the style gap.
Abstract: Learning pixel representations of games can benefit artificial intelligence across several downstream tasks including game-playing agents, procedural content generation, and player modeling. However, the generalizability of these methods remains a challenge, as learned representations should ideally be shared across games with similar game mechanics. This could allow, for instance, game-playing agents trained on one game to perform well in similar games with no re-training. This paper explores how generalizable pre-trained computer vision encoders can be used for such tasks by decomposing the latent space into content and style embeddings. The goal is to minimize the domain gap between games of the same genre when it comes to game content and ignore differences in graphical style. We employ a pre-trained Vision Transformer encoder and a decomposition technique based on game genres to obtain separate content and style embeddings. Our findings show that the decomposed embeddings achieve style invariance across multiple games while still maintaining strong content extraction capabilities. We argue that the proposed decomposition of content and style offers better generalization across game environments independently of the downstream task.
in Proceedings of the BMVC workshop on Computer Vision for Games and Games for Computer Vision, 2023. BibTex
From the Lab to the Wild: Affect Modeling via Privileged Information
Konstantinos Makantasis, Kosmas Pinitas, Antonios Liapis and Georgios N. Yannakakis
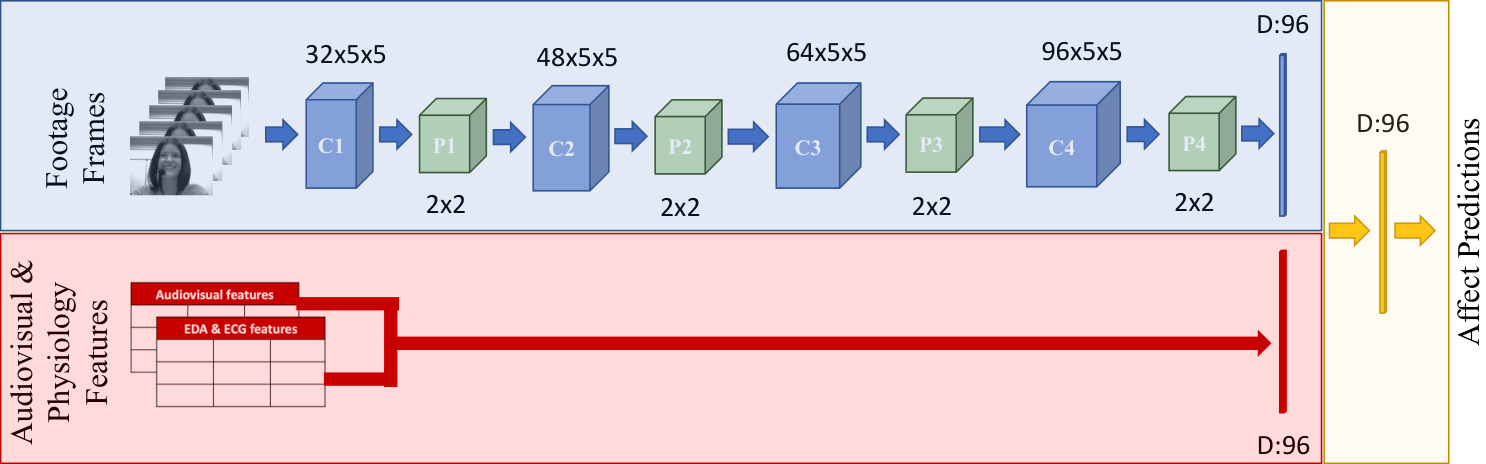
Architecture of the employed models of affect. The blue-shaded stream is based on webcam footage encoded into frames, and constitutes non-privileged information that may be available in the wild. The red stream and yellow-shaded module fuse information from other modalities (e.g. physiology, processed audio metrics) that we treat as privileged; these modalities may not be available or may require specialized software to produce in the wild. The transfer of knowledge in this paper is achieved by feeding the model with only those modalities on information that is available in the wild and force it during training to balance between the learning task's loss and learning latent representations that match those of the teacher model which is trained on privileged information.
Abstract: How can we reliably transfer affect models trained in controlled laboratory conditions (in-vitro) to uncontrolled real-world settings (in-vivo)? The information gap between in-vitro and in-vivo applications defines a core challenge of affective computing. This gap is caused by limitations related to affect sensing including intrusiveness, hardware malfunctions and availability of sensors. As a response to these limitations, we introduce the concept of privileged information for operating affect models in real-world scenarios (in the wild). Privileged information enables affect models to be trained across multiple modalities available in a lab, and ignore, without significant performance drops, those modalities that are not available when they operate in the wild. Our approach is tested in two multimodal affect databases one of which is designed for testing models of affect in the wild. By training our affect models using all modalities and then using solely raw footage frames for testing the models, we reach the performance of models that fuse all available modalities for both training and testing. The results are robust across both classification and regression affect modeling tasks which are dominant paradigms in affective computing. Our findings make a decisive step towards realizing affect interaction in the wild.
in IEEE Transactions on Affective Computing 15(2), 2024. BibTex
The Pixels and Sounds of Emotion: General-Purpose Representations of Arousal in Games
Konstantinos Makantasis, Antonios Liapis and Georgios N. Yannakakis
Screenshots of the four tested games, and the activation map of the classifier trained to predict high or low arousal. Warmer colors in the activation maps show which areas of the screen most impact the prediction of high arousal.
Abstract: What if emotion could be captured in a general and subject-agnostic fashion? Is it possible, for instance, to design general-purpose representations that detect affect solely from the pixels and audio of a human-computer interaction video? In this paper we address the above questions by evaluating the capacity of deep learned representations to predict affect by relying only on audiovisual information of videos. We assume that the pixels and audio of an interactive session embed the necessary information required to detect affect. We test our hypothesis in the domain of digital games and evaluate the degree to which deep classifiers and deep preference learning algorithms can learn to predict the arousal of players based only on the video footage of their gameplay. Our results from four dissimilar games suggest that general-purpose representations can be built across games as the arousal models obtain average accuracies as high as 85% using the challenging leave-one-video-out cross-validation scheme. The dissimilar audiovisual characteristics of the tested games showcase the strengths and limitations of the proposed method.
in IEEE Transactions on Affective Computing 14(1), 2023. BibTex
Game State Learning via Game Scene Augmentation
Chintan Trivedi, Konstantinos Makantasis, Antonios Liapis and Georgios N. Yannakakis

The proposed GameCLR method uses the CARLA game engine to first apply game scene augmentation before going through rendering the game-state as an image, and then applying regular image augmentations.
Abstract: Having access to accurate game state information is of utmost importance for any artificial intelligence task including game-playing, testing, player modeling, and procedural content generation. Self-Supervised Learning (SSL) techniques have shown to be capable of inferring accurate game state information from the high-dimensional pixel input of game footage into compressed latent representations. Contrastive Learning is a popular SSL paradigm where the visual understanding of the game's images comes from contrasting dissimilar and similar game states defined by simple image augmentation methods. In this study, we introduce a new game scene augmentation technique - named GameCLR - that takes advantage of the game-engine to define and synthesize specific, highly-controlled renderings of different game states, thereby, boosting contrastive learning performance. We test our GameCLR technique on images of the CARLA driving simulator environment and compare it against the popular SimCLR baseline SSL method. Our results suggest that GameCLR can infer the game's state information from game footage more accurately compared to the baseline. Our proposed approach allows us to conduct game artificial intelligence research by directly utilizing screen pixels as input.
in Proceedings of the Foundations on Digital Games Conference, 2022. BibTex
Open-Ended Evolution for Minecraft Building Generation
Matthew Barthet, Antonios Liapis and Georgios N. Yannakakis
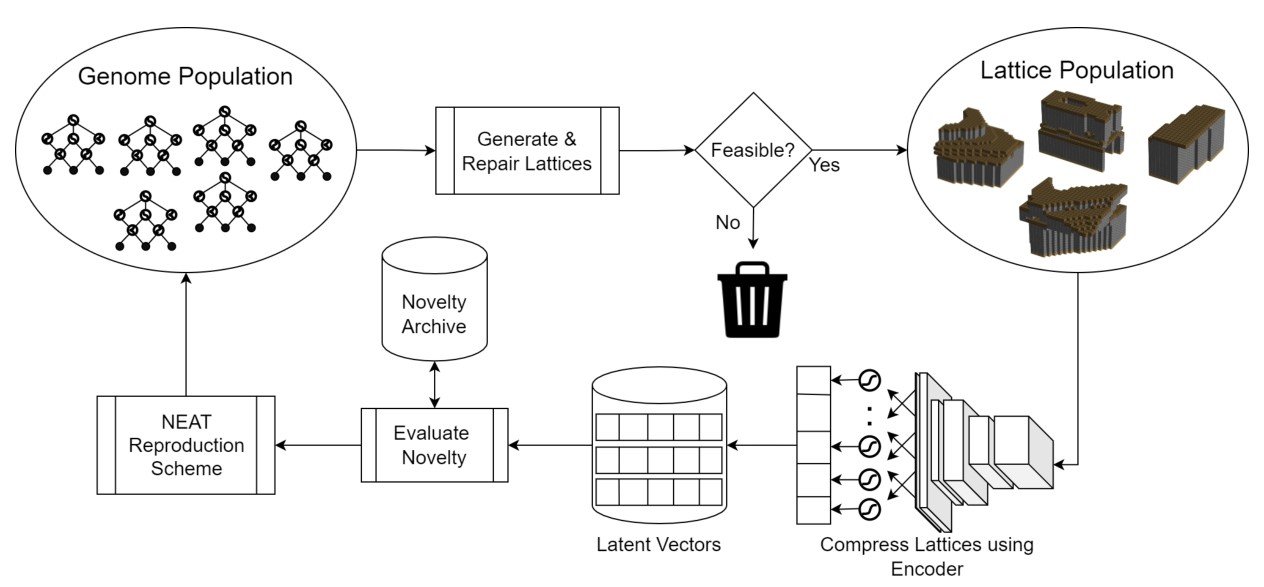
The exploration phase performs novelty search on the latent space by encoding the Minecraft buildings that are being evolved.
Abstract: This paper proposes a procedural content generator which evolves Minecraft buildings according to an open-ended and intrinsic definition of novelty. To realize this goal we evaluate individuals' novelty in the latent space using a 3D autoencoder, and alternate between phases of exploration and transformation. During exploration the system evolves multiple populations of CPPNs through CPPN-NEAT and constrained novelty search in the latent space (defined by the current autoencoder). We apply a set of repair and constraint functions to ensure candidates adhere to basic structural rules and constraints during evolution. During transformation, we reshape the boundaries of the latent space to identify new interesting areas of the solution space by retraining the autoencoder with novel content. In this study we evaluate five different approaches for training the autoencoder during transformation and its impact on populations' quality and diversity during evolution. Our results show that by retraining the autoencoder we can achieve better open-ended complexity compared to a static model, which is further improved when retraining using larger datasets of individuals with diverse complexities.
in IEEE Transactions on Games 15(4), 2022. BibTex
Learning Task-Independent Game State Representations from Unlabeled Images
Chintan Trivedi, Konstantinos Makantasis, Antonios Liapis and Georgios N. Yannakakis
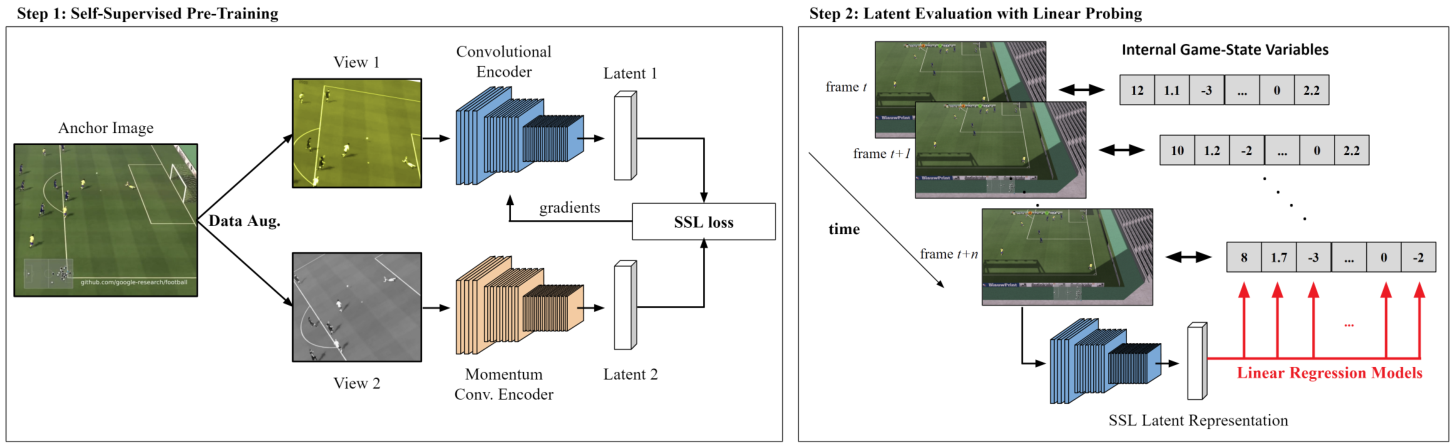
Implemented two-step process, first pre-training the Convolutional Encoder using SSL and then evaluating the learned representations with Linear Probing on the test set.
Abstract: Self-supervised learning (SSL) techniques have been widely used to learn compact and informative representations from high-dimensional complex data. In many computer vision tasks, such as image classification, such methods achieve state-of-the-art results that surpass supervised learning approaches. In this paper, we investigate whether SSL methods can be leveraged for the task of learning accurate state representations of games, and if so, to what extent. For this purpose, we collect game footage frames and corresponding sequences of games' internal state from three different 3D games: VizDoom, the CARLA racing simulator and the Google Research Football Environment. We train an image encoder with three widely used SSL algorithms using solely the raw frames, and then attempt to recover the internal state variables from the learned representations. Our results across all three games showcase significantly higher correlation between SSL representations and the game's internal state compared to pre-trained baseline models such as ImageNet. Such findings suggest that SSL-based visual encoders can yield general--not tailored to a specific task--yet informative game representations solely from game pixel information. Such representations can, in turn, form the basis for boosting the performance of downstream learning tasks in games, including gameplaying, content generation and player modeling.
in Proceedings of the IEEE Conference on Games, 2022. BibTex
Seeding Diversity into AI Art
Marvin Zammit, Antonios Liapis and Georgios N. Yannakakis

Images generated via Novelty Search with Local Competition on a latent vector previously optimized through a Generative Adversarial Algorithm.
Abstract: This paper argues that generative art driven by conformance to a visual and/or semantic corpus lacks the necessary criteria to be considered creative. Among several issues identified in the literature, we focus on the fact that generative adversarial networks (GANs) that create a single image, in a vacuum, lack a concept of novelty regarding how their product differs from previously created ones. We envision that an algorithm that combines the novelty preservation mechanisms in evolutionary algorithms with the power of GANs can deliberately guide its creative process towards output that is both good and novel. In this paper, we use recent advances in image generation based on semantic prompts using OpenAI's CLIP model, interrupting the GAN's iterative process with short cycles of evolutionary divergent search. The results of evolution are then used to continue the GAN's iterative process; we hypothesise that this intervention will lead to more novel outputs. Testing our hypothesis using novelty search with local competition, a quality-diversity evolutionary algorithm that can increase visual diversity while maintaining quality in the form of adherence to the semantic prompt, we explore how different notions of visual diversity can affect both the process and the product of the algorithm. Results show that even a simplistic measure of visual diversity can help counter a drift towards similar images caused by the GAN. This first experiment opens a new direction for introducing higher intentionality and a more nuanced drive for GANs.
in Proceedings of the International Conference on Computational Creativity, 2022. BibTex
RankNEAT: Outperforming Stochastic Gradient Search in Preference Learning Tasks
Kosmas Pinitas, Konstantinos Makantasis, Antonios Liapis and Georgios N. Yannakakis

Eigen-CAM visualization of game footage features that impact player arousal predictions in a platformer game.
Abstract: Stochastic gradient descent (SGD) is a premium optimization method for training neural networks, especially for learning objectively defined labels such as image objects and events. When a neural network is instead faced with subjectively defined labels - such as human demonstrations or annotations - SGD may struggle to explore the deceptive and noisy loss landscapes caused by the inherent bias and subjectivity of humans. While neural networks are often trained via preference learning algorithms in an effort to eliminate such data noise, the de facto training methods rely on gradient descent. Motivated by the lack of empirical studies on the impact of evolutionary search to the training of preference learners, we introduce the RankNEAT algorithm which learns to rank through neuroevolution of augmenting topologies. We test the hypothesis that RankNEAT outperforms traditional gradient-based preference learning within the affective computing domain, in particular predicting annotated player arousal from the game footage of three dissimilar games. RankNEAT yields superior performances compared to the gradient-based preference learner (RankNet) in the majority of experiments since its architecture optimization capacity acts as an efficient feature selection mechanism, thereby, eliminating overfitting. Results suggest that RankNEAT is a viable and highly efficient evolutionary alternative to preference learning.
in Proceedings of the Genetic and Evolutionary Computation Conference, 2022. BibTex
AffectGAN: Affect-Based Generative Art Driven by Semantics
Theodoros Galanos, Antonios Liapis and Georgios N. Yannakakis

Two images generated via AffectGAN for a cityscape prompt: the left image is generated for "a happy cityscape" and the right image is generated for "a depressed cityscape".
Abstract: This paper introduces a novel method for generating artistic images that express particular affective states. Leveraging state-of-the-art deep learning methods for visual generation (through generative adversarial networks), semantic models from OpenAI, and the annotated dataset of the visual art encyclopedia WikiArt, our AffectGAN model is able to generate images based on specific or broad semantic prompts and intended affective outcomes. A small dataset of 32 images generated by AffectGAN is annotated by 50 participants in terms of the particular emotion they elicit, as well as their quality and novelty. Results show that for most instances the intended emotion used as a prompt for image generation matches the participants' responses. This small-scale study brings forth a new vision towards blending affective computing with computational creativity, enabling generative systems with intentionality in terms of the emotions they wish their output to elicit.
in Proceedings of the ACII Workshop on What's Next in Affect Modeling?, 2021. BibTex
Privileged Information for Modeling Affect In The Wild
Konstantinos Makantasis, David Melhart, Antonios Liapis and Georgios N. Yannakakis
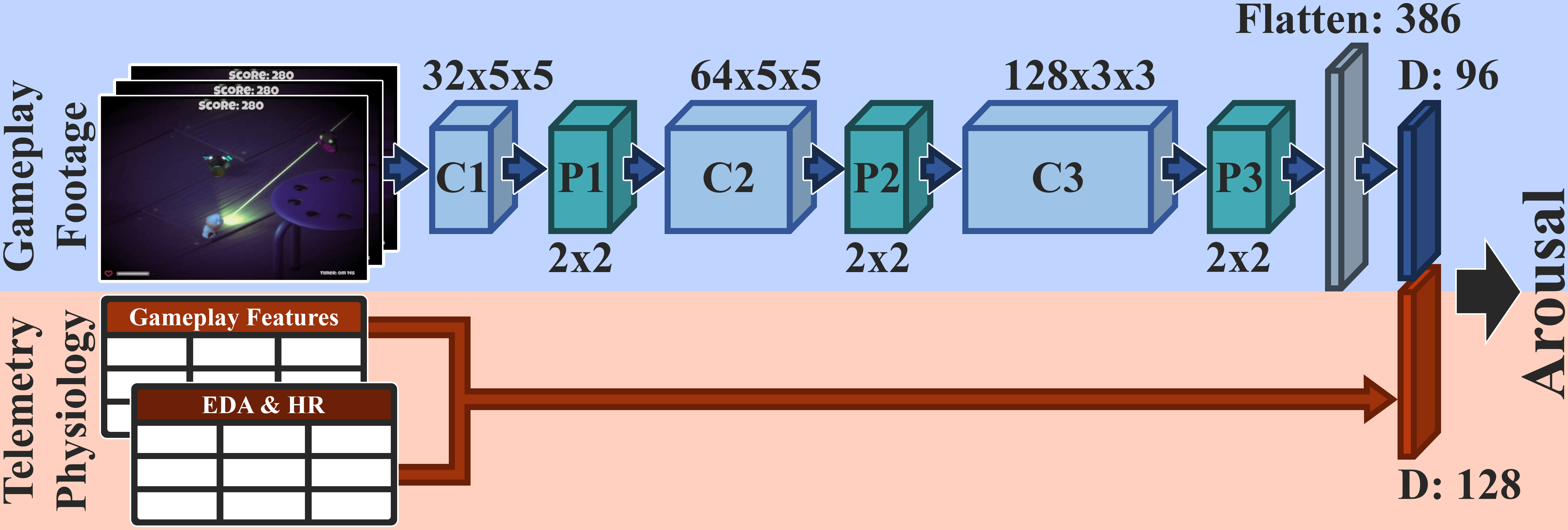
Gameplay footage in the student model is combined with physiological signals and game telemetry in the teacher model. In the wild, the privileged information (biosignal and game telemetry data) is unavailable.
Abstract: A key challenge of affective computing research is discovering ways to reliably transfer affect models that are built in the laboratory to real world settings, namely in the wild. The existing gap between in vitro} and in vivo affect applications is mainly caused by limitations related to affect sensing including intrusiveness, hardware malfunctions, availability of sensors, but also privacy and security. As a response to these limitations in this paper we are inspired by recent advances in machine learning and introduce the concept of privileged information for operating affect models in the wild. The presence of privileged information enables affect models to be trained across multiple modalities available in a lab setting and ignore modalities that are not available in the wild with no significant drop in their modeling performance. The proposed privileged information framework is tested in a game arousal corpus that contains physiological signals in the form of heart rate and electrodermal activity, game telemetry, and pixels of footage from two dissimilar games that are annotated with arousal traces. By training our arousal models using all modalities (in vitro) and using solely pixels for testing the models (in vivo), we reach levels of accuracy obtained from models that fuse all modalities both for training and testing. The findings of this paper make a decisive step towards realizing affect interaction in the wild.
in Proceedings of the IEEE International Conference on Affective Computing and Intelligent Interaction, 2021. BibTex
Contrastive Learning of Generalized Game Representations
Chintan Trivedi, Antonios Liapis and Georgios N. Yannakakis

t-SNE rendering of the validation set of ten different genres of sports games. Contrastive learning offers a much better clustering quality than purely supervised or pre-trained ResNet50 networks.
Abstract: Representing games through their pixels offers a promising approach for building general-purpose and versatile game models. While games are not merely images, neural network models trained on game pixels often capture differences of the visual style of the image rather than the content of the game. As a result, such models cannot generalize well even within similar games of the same genre. In this paper we build on recent advances in contrastive learning and showcase its benefits for representation learning in games. Learning to contrast images of games not only classifies games in a more efficient manner; it also yields models that separate games in a more meaningful fashion by ignoring the visual style and focusing, instead, on their content. Our results in a large dataset of sports video games containing 100k images across 175 games and 10 game genres suggest that contrastive learning is better suited for learning generalized game representations compared to conventional supervised learning. The findings of this study bring us closer to universal visual encoders for games that can be reused across previously unseen games without requiring retraining or fine-tuning.
in Proceedings of the IEEE Conference on Games, 2021. BibTex
ARCH-Elites: Quality-Diversity for Urban Design
Theodoros Galanos, Antonios Liapis, Georgios N. Yannakakis and Reinhard Koenig
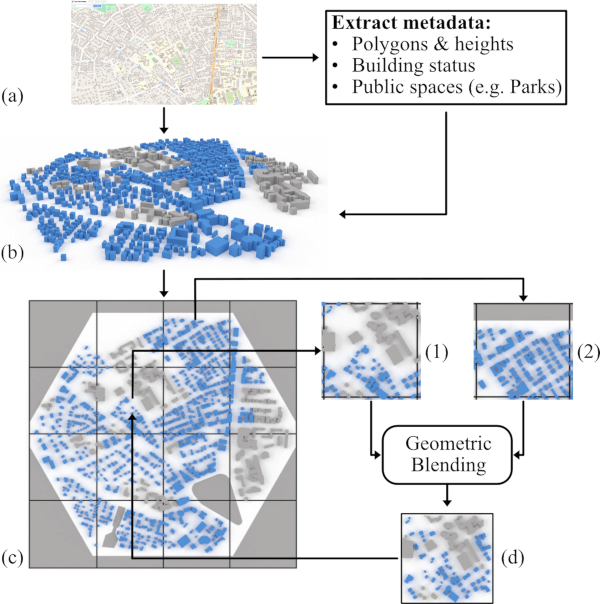
Evolution in ARCH-Elites: A geographic location is selected by the user (a) and building geometries and metadata are extracted (b). The location is then split into cells (c); two cells are selected and geometric blending takes place (d).
Abstract: This paper introduces ARCH-Elites, a MAP-Elites implementation that can reconfigure large-scale urban layouts at real-world locations via a pre-trained surrogate model instead of costly simulations. In a series of experiments, we generate novel urban designs for two real-world locations in Boston, Massachusetts. Combining the exploration of a possibility space with real-time performance evaluation creates a powerful new paradigm for architectural generative design that can extract and articulate design intelligence.
in Proceedings of the Genetic and Evolutionary Computation Conference, 2021. BibTex
SuSketch: Surrogate Models of Gameplay as a Design Assistant
Panagiotis Migkotzidis and Antonios Liapis
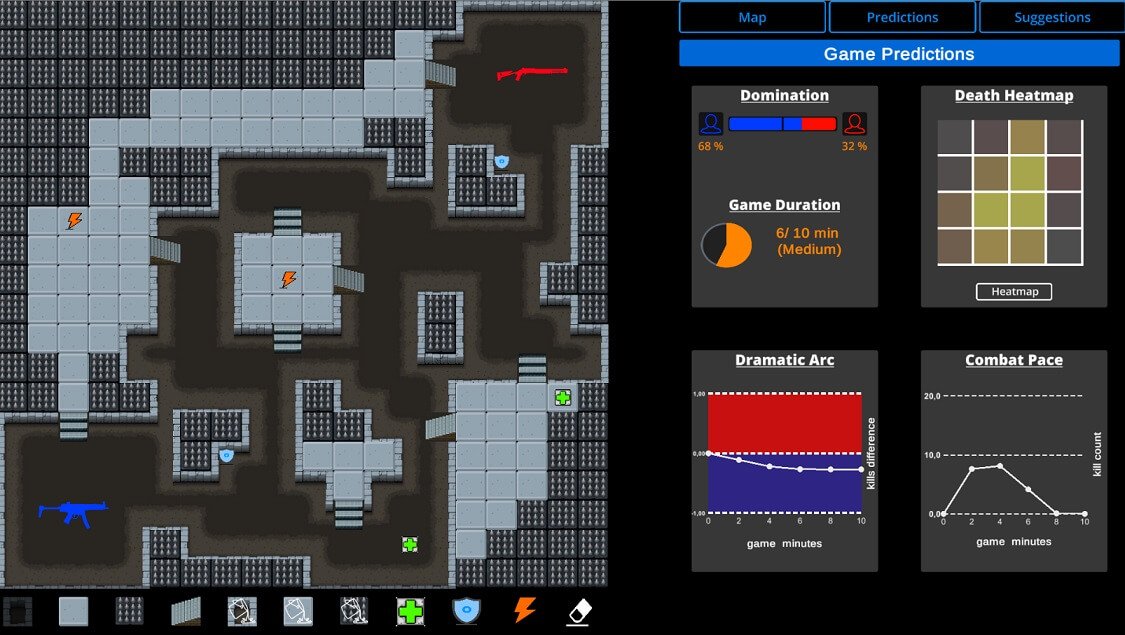
SuSketch drawing interface: the designer draws their desired level via the canvas and tile palette (left half) and the computer predicts a number of gameplay outcomes (aggregated, spatial, or temporal) and visualizes them back to the designer (right half)
Abstract: This paper introduces SuSketch, a design tool for first person shooter levels. SuSketch provides the designer with gameplay predictions for two competing players of specific character classes. The interface allows the designer to work side-by-side with an artificially intelligent creator and to receive varied types of feedback such as path information, predicted balance between players in a complete playthrough, or a predicted heatmap of the locations of player deaths. The system also proactively designs alternatives to the level and class pairing, and presents them to the designer as suggestions that improve the predicted balance of the game. SuSketch offers a new way of integrating machine learning into mixed-initiative co-creation tools, as a surrogate of human play trained on a large corpus of artificial playtraces. A user study with 16 game developers indicated that the tool was easy to use, but also highlighted a need to make SuSketch more accessible and more explainable.
in IEEE Transactions on Games 14(2), pp. 273-283. 2021. BibTex
Dungeons & Replicants: Automated Game Balancing via Deep Player Behavior Modeling
Johannes Pfau, Antonios Liapis, Georg Volkmar, Georgios N. Yannakakis and Rainer Malaka

In-game screenshot of the PvE benchmark in Aion, where player replicas encounter 100 heuristic opponents with increasing difficulty in one-on-one situations (attack horizontally, maxHP vertically).
Abstract: Balancing the options available to players in a way that ensures rich variety and viability is a vital factor for the success of any video game, and particularly competitive multiplayer games. Traditionally, this balancing act requires extensive periods of expert analysis, play testing and debates. While automated gameplay is able to predict outcomes of parameter changes, current approaches mainly rely on heuristic or optimal strategies to generate agent behavior. In this paper, we demonstrate the use of deep player behavior models to represent a player population (n = 213) of the massively multiplayer online role-playing game Aion, which are used, in turn, to generate individual agent behaviors. Results demonstrate significant balance differences in opposing enemy encounters and show how these can be regulated. Moreover, the analytic methods proposed are applied to identify the balance relationships between classes when fighting against each other, reflecting the original developers' design.
in Proceedings of the IEEE Conference on Games, 2020. BibTex
Modelling the Quality of Visual Creations in Iconoscope
Antonios Liapis, Daniele Gravina, Emil Kastbjerg and Georgios N. Yannakakis

Network architecture for late multimodal fusion of icons' visuals and summary statistics.
Abstract: This paper presents the current state of the online game Iconoscope and analyzes the data collected from almost 45 months of continuous operation. Iconoscope is a freeform creation game which aims to foster the creativity of its users through diagrammatic lateral thinking, as users are required to depict abstract concepts as icons which may be misinterpreted by other users as different abstract concepts. From users' responses collected from an online gallery of all icons drawn with Iconoscope, we collect a corpus of over 500 icons which contain annotations of visual appeal. Several machine learning algorithms are tested for their ability to predict the appeal of an icon from its visual appearance and other properties. findings show the impact of the representation on the model's accuracy and highlight how such a predictive model of quality can be applied to evaluate new icons (human-authored or generated).
in Proceedings of the 8th International Games and Learning Alliance Conference. Springer, 2019. BibTex
Using Dates as Contextual Information for Personalized Cultural Heritage Experiences
Ahmed Dahroug, Andreas Vlachidis, Antonios Liapis, Antonis Bikakis, Martin Lopez-Nores, Owen Sacco and Jose Juan Pazos-Arias

Associations discovered, explained, and visualized for a synthetic persona (a naturist German couple) visiting the Archaeological Museum of Tripoli and interested in the keywords "Nudity", "Marriage" and "Mythology"
Abstract: We present semantics-based mechanisms that aim to promote reflection on cultural heritage by means of dates (historical events or annual commemorations), owing to their connections to a collection of items and to the visitors' interests. We argue that links to specific dates can trigger curiosity, increase retention and guide visitors around the venue following new appealing narratives in subsequent visits. The proposal has been evaluated in a pilot study on the collection of the Archaeological Museum of Tripoli (Greece), for which a team of humanities experts wrote a set of diverse narratives about the exhibits. A year-round calendar was crafted so that certain narratives would be more or less relevant on any given day. Expanding on this calendar, personalised recommendations can be made by sorting out those relevant narratives according to personal events and interests recorded in the profiles of the target users. Evaluation of the associations by experts and potential museum visitors shows that the proposed approach can discover meaningful connections, while many others that are more incidental can still contribute to the intended cognitive phenomena.
in SAGE Journal of Information Science 47(1), pp. 82-100, 2021. BibTex
A Multi-Faceted Surrogate Model for Search-based Procedural Content Generation
Daniel Karavolos, Antonios Liapis and Georgios N. Yannakakis
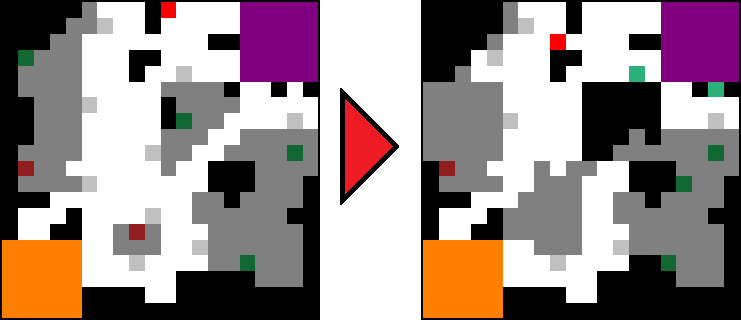
Using a human-made level as a seed, multi-objective evolution based on a surrogate model of quality manages to improve the level towards longer matches with a balanced match outcome between a Scout (as Player 1) and a Heavy (as Player 2).
Abstract: This paper proposes a framework for the procedural generation of level and ruleset components of games via a surrogate model that assesses their quality and complementarity. The surrogate model combines level and ruleset elements as input and gameplay outcomes as output, thus constructing a mapping between three different facets of games. Using this model as a surrogate for expensive gameplay simulations, a search-based generator can adapt content towards a target gameplay outcome. Using a shooter game as the target domain, this paper explores how parameters of the players' character classes can be mapped to both the level's representation and the gameplay outcomes of balance and match duration. The surrogate model is built on a deep learning architecture, trained on a large corpus of randomly generated sets of levels, classes and simulations from gameplaying agents. Results show that a search-based generative approach can adapt character classes, levels, or both towards designer-specified targets. The model can thus act as a design assistant or be integrated in a mixed-initiative tool. Most importantly, the combination of three game facets into the model allows it to identify the synergies between levels, rules and gameplay and orchestrate the generation of the former two towards desired outcomes.
in Transactions on Games, vol. 13, no 1, pp. 11-22, 2021. BibTex
From Pixels to Affect: A Study on Games and Player Experience
Konstantinos Makantasis, Antonios Liapis and Georgios N. Yannakakis
GRAD-CAM visualization, showing the areas of the game screen which corresponds to a high activation of the model of players' arousal level.
Abstract: Is it possible to predict the affect of a user just by observing her behavioral interaction through a video? How can we, for instance, predict a user's arousal in games by merely looking at the screen during play? In this paper we address these questions by employing three dissimilar deep convolutional neural network architectures in our attempt to learn the underlying mapping between video streams of gameplay and the player's arousal. We test the algorithms in an annotated dataset of 50 gameplay videos of a survival shooter game and evaluate the deep learned models' capacity to classify high vs low arousal levels. Our key findings with the demanding leave-one- video-out validation method reveal accuracies of over 78% on average and 98% at best. While this study focuses on games and player experience as a test domain, the findings and methodology are directly relevant to any affective computing area, introducing a general and user-agnostic approach for modeling affect.
in Proceedings of the International Conference on Affective Computing and Intelligent Interaction, 2019. BibTex
PyPLT: Python Preference Learning Toolbox
Elizabeth Camilleri, Georgios N. Yannakakis, David Melhart and Antonios Liapis
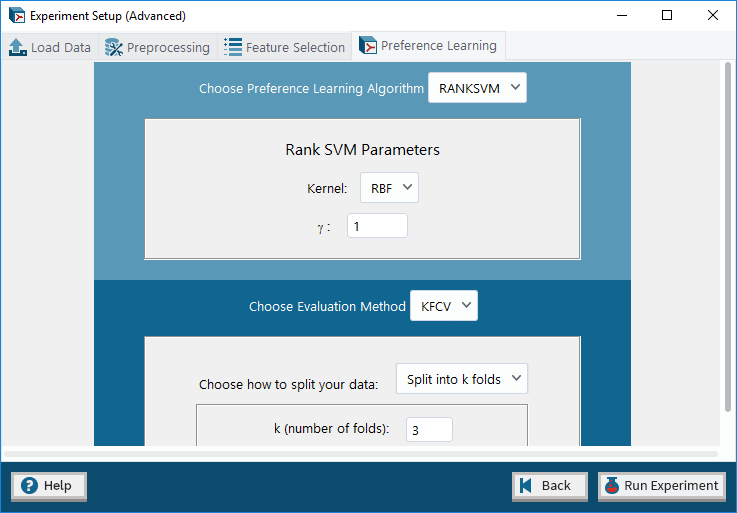
Editor interface for pyPLT, where advanced users can customize their preference learning algorithms' parameters.
Abstract: There is growing evidence suggesting that subjective values such as emotions are intrinsically relative and that an ordinal approach is beneficial to their annotation and analysis. Ordinal data processing yields more reliable, valid and general predictive models, and preference learning algorithms have shown a strong advantage in deriving computational models from such data. To enable the extensive use of ordinal data processing and preference learning, this paper introduces the Python Preference Learning Toolbox. The toolbox is open source, features popular preference learning algorithms and methods, and is designed to be accessible to a wide audience of researchers and practitioners. The toolbox is evaluated with regards to both the accuracy of its predictive models across two affective datasets and its usability via a user study. Our key findings suggest that the implemented algorithms yield accurate models of affect while its graphical user interface is suitable for both novice and experienced users.
in Proceedings of the International Conference on Affective Computing and Intelligent Interaction, 2019. BibTex
Pairing Character Classes in a Deathmatch Shooter Game via a Deep-Learning Surrogate Model
Daniel Karavolos, Antonios Liapis and Georgios N. Yannakakis
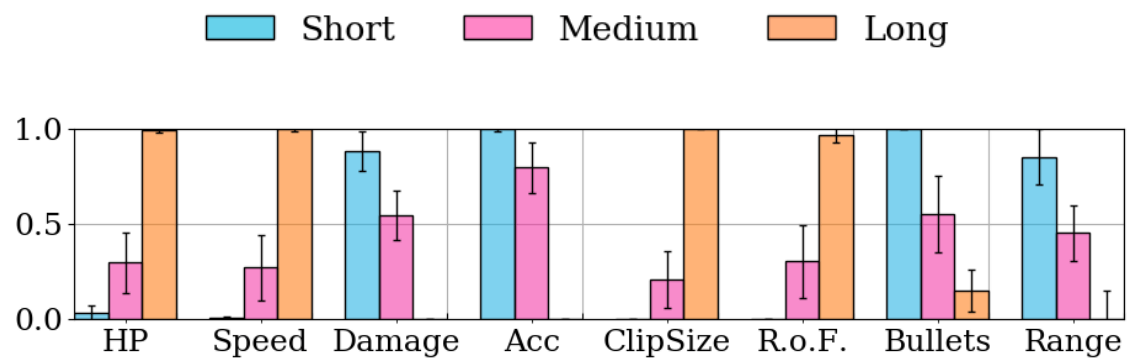
Trends of a player's class parameters, evolved towards longer or shorter matches. Results are averaged from evolutionary runs on 20 different levels.
Abstract: This paper introduces a surrogate model of gameplay that learns the mapping between different game facets, and applies it to a generative system which designs new content in one of these facets. Focusing on the shooter game genre, the paper explores how deep learning can help build a model which combines the game level structure and the game's character class parameters as input and the gameplay outcomes as output. The model is trained on a large corpus of game data from simulations with artificial agents in random sets of levels and class parameters. The model is then used to generate classes for specific levels and for a desired game outcome, such as balanced matches of short duration. findings in this paper show that the system can be expressive and can generate classes for both computer generated and human authored levels.
in Proceedings of the FDG Workshop on Procedural Content Generation, 2018. BibTex
Explainable AI for Designers: A Human-Centered Perspective on Mixed-Initiative Co-Creation
Jichen Zhu, Antonios Liapis, Sebastian Risi, Rafael Bidarra and G. Michael Youngblood
Abstract: Growing interest in eXplainable Artificial Intelligence (XAI) aims to make AI and machine learning more understandable to human users. However, most existing work focuses on new algorithms, and not on usability, practical interpretability and efficacy on real users. In this vision paper, we propose a new research area of eXplainable AI for Designers (XAID), specifically for game designers. By focusing on a specific user group, their needs and tasks, we propose a human-centered approach for facilitating game designers to co-create with AI/ML techniques through XAID. We illustrate our initial XAID framework through three use cases, which require an understanding both of the innate properties of the AI techniques and users' needs, and we identify key open challenges.
in Proceedings of the IEEE Conference on Computational Intelligence and Games, 2018. BibTex
Using a Surrogate Model of Gameplay for Automated Level Design
Daniel Karavolos, Antonios Liapis and Georgios N. Yannakakis
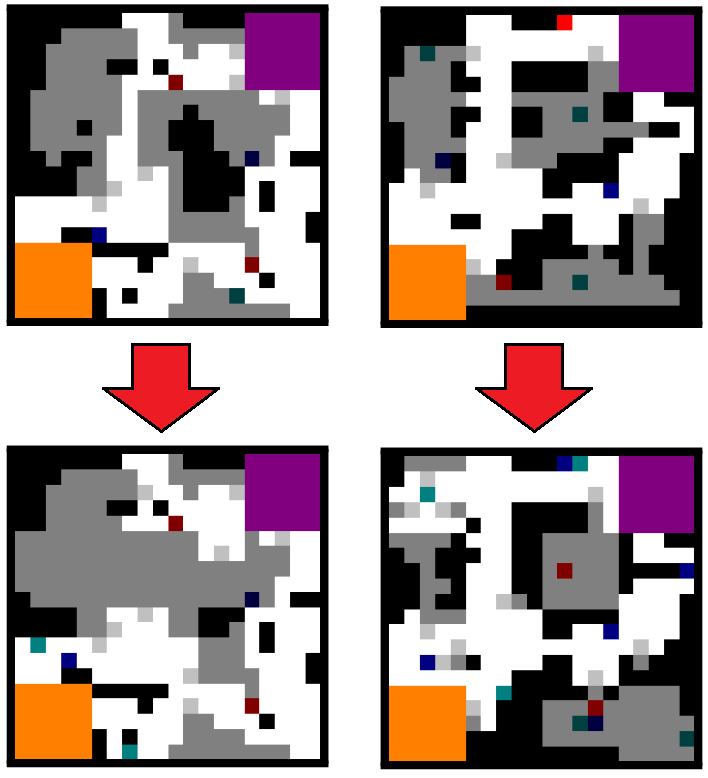
Initial maps (generated: top left, designed: top right) and their adapted versions (bottom) via surrogate-based evolution. The bottom left map is evolved towards balanced, medium duration matches with player 1 as a Heavy and player 2 as a Scout. The bottom right map is evolved towards balanced, long duration matches with player 1 as a Scout and player 2 as a Pyro.
Abstract: This paper describes how a surrogate model of the interrelations between different types of content in the same game can be used for level generation. Specifically, the model associates level structure and game rules with gameplay outcomes in a shooter game. We use a deep learning approach to train a model on simulated playthroughs of two-player deathmatch games, in diverse levels and with different character classes per player. findings in this paper show that the model can predict the duration and winner of the match given a top-down map of the level and the parameters of the two players' character classes. With this surrogate model in place, we investigate which level structures would result in a balanced match of short, medium or long duration for a given set of character classes. Using evolutionary computation, we are able to discover levels which improve the balance between different classes. This opens up potential applications for a designer tool which can adapt a human authored map to fit the designer's desired gameplay outcomes, taking account of the game's rules.
in Proceedings of the IEEE Conference on Computational Intelligence and Games, 2018. BibTex
Towards General Models of Player Affect
Elizabeth Camilleri, Georgios N. Yannakakis and Antonios Liapis
The three games played and annotated by users; the paper tests how well a computational model of arousal which learned from annotations in two games predicts annotations in the third.
Abstract: While the primary focus of affective computing has been on constructing efficient and reliable models of affect, the vast majority of such models are limited to a specific task and domain. This paper, instead, investigates how computational models of affect can be general across dissimilar tasks; in particular, in modeling the experience of playing very different video games. We use three dissimilar games whose players annotated their arousal levels on video recordings of their own playthroughs. We construct models mapping ranks of arousal to skin conductance and gameplay logs via preference learning and we use a form of cross-game validation to test the generality of the obtained models on unseen games. Our initial results comparing between absolute and relative measures of the arousal annotation values indicate that we can obtain more general models of player affect if we process the model output in an ordinal fashion.
In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, 2017. BibTex
Learning the Patterns of Balance in a Multi-Player Shooter Game
Daniel Karavolos, Antonios Liapis and Georgios N. Yannakakis

Architecture of the convolutional neural network that predicts whether a shooter game matchup will be balanced based on the visual layout of the level and the parameters of two teams' weapons.
Abstract: A particular challenge of the game design process is when the designer is requested to orchestrate dissimilar elements of games such as visuals, audio, narrative and rules to achieve a specific play experience. Within the domain of adversarial first person shooter games, for instance, a designer must be able to comprehend the differences between the weapons available in the game, and appropriately craft a game level to take advantage of strengths and weaknesses of those weapons. As an initial study towards computationally orchestrating dissimilar content generators in games, this paper presents a computational model which can classify a matchup of a team-based shooter game as balanced or as favoring one or the other team. The computational model uses convolutional neural networks to learn how game balance is affected by the level, represented as an image, and each team's weapon parameters. The model was trained on a corpus of over 50,000 simulated games with artificial agents on a diverse set of levels created by 39 different generators. The results show that the fusion of levels, when processed by a convolutional neural network, and weapon parameters yields an accuracy far above the baseline but also improves accuracy compared to artificial neural networks or models which use partial information, such as only the weapon or only the level as input.
In Proceedings of the FDG workshop on Procedural Content Generation in Games, 2017. BibTex
Transforming Exploratory Creativity with DeLeNoX
Antonios Liapis, Hector P. Martinez, Julian Togelius and Georgios N. Yannakakis

Progressive complexification of generated spaceships trained with new features in every iteration.
Abstract: We introduce DeLeNoX (Deep Learning Novelty Explorer), a system that autonomously creates artifacts in constrained spaces according to its own evolving interestingness criterion. DeLeNoX proceeds in alternating phases of exploration and transformation. In the exploration phases, a version of novelty search augmented with constraint handling searches for maximally diverse artifacts using a given distance function. In the transformation phases, a deep learning autoencoder learns to compress the variation between the found artifacts into a lower-dimensional space. The newly trained encoder is then used as the basis for a new distance function, transforming the criteria for the next exploration phase. In the current paper, we apply DeLeNoX to the creation of spaceships suitable for use in two-dimensional arcade-style computer games, a representative problem in procedural content generation in games. We also situate DeLeNoX in relation to the distinction between exploratory and transformational creativity, and in relation to Schmidhuber's theory of creativity through the drive for compression progress.
in Proceedings of the Fourth International Conference on Computational Creativity, 2013, pp. 56-63. BibTex
Sentient World: Human-Based Procedural Cartography
Antonios Liapis, Georgios N. Yannakakis and Julian Togelius
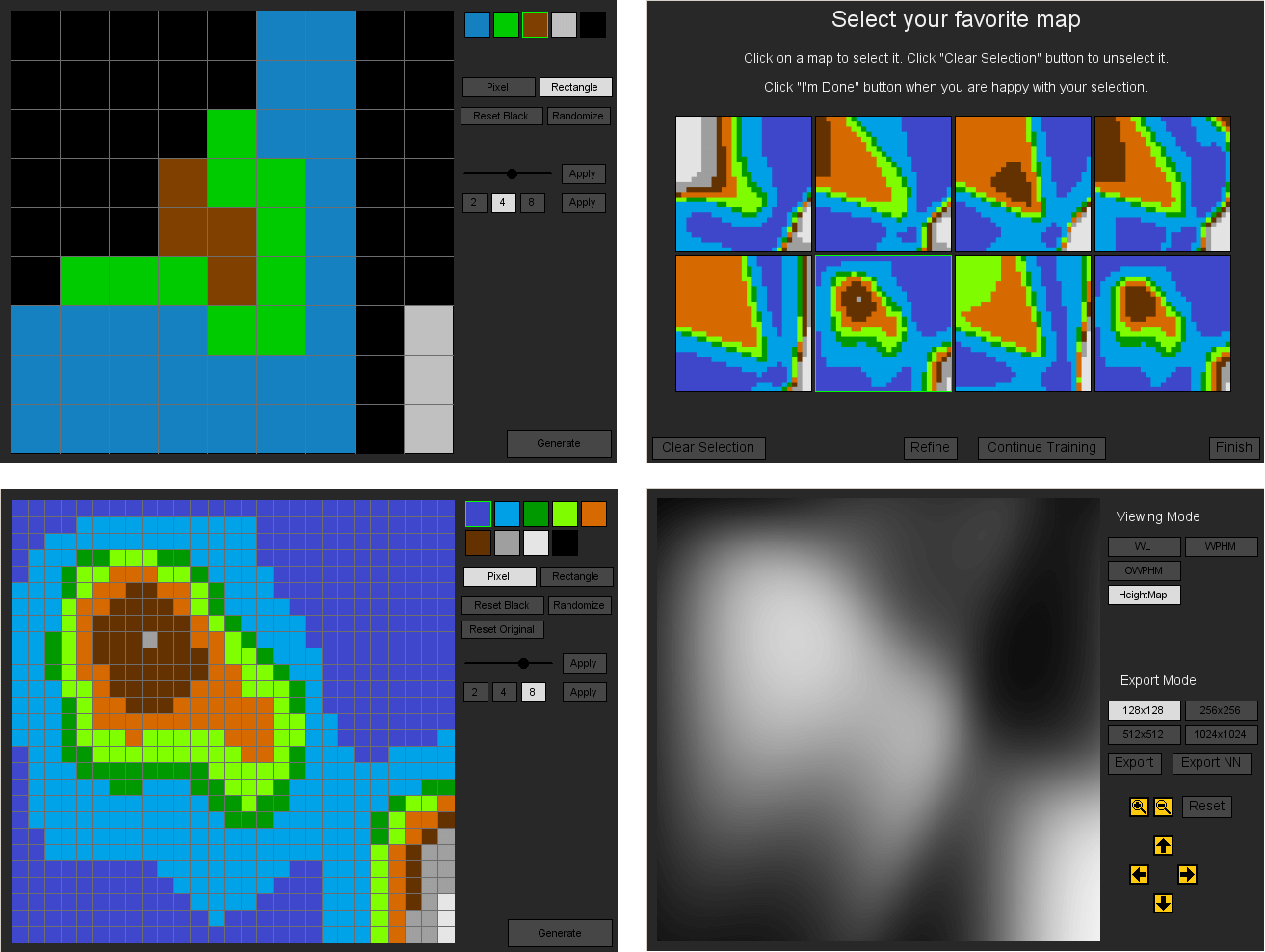
Different steps of the design process of terrain using Sentient World: the user draws a rough terrain sketch using coarse height brushes (top left), which Sentient World refines and shows possible higher-detail maps to the user (top right). The user can manual edit the refined map and submit it for further refinement (bottom left), while the final output is a map of infinite resolution which can be visualized in many different ways (bottom right).
Abstract: This paper presents a first step towards a mixed-initiative tool for the creation of game maps. The tool, named Sentient World, allows the designer to draw a rough terrain sketch, adding extra levels of detail through stochastic and gradient search. Novelty search generates a number of dissimilar artificial neural networks that are trained to approximate a designer's sketch and provide maps of higher resolution back to the designer. As the procedurally generated maps are presented to the designer (to accept, reject, or edit) the terrain sketches are iteratively refined into complete high resolution maps which may diverge from initial designer concepts. The tool supports designer creativity while conforming to designer intentions, and maintains constant designer control through the map selection and map editing options. Results obtained on a number of test maps show that novelty search is beneficial for introducing divergent content to the designer without reducing the speed of iterative map refinement.
in Proceedings of Evolutionary and Biologically Inspired Music, Sound, Art and Design (EvoMusArt), vol. 7834, LNCS. Springer, 2013, pp. 180-191. BibTex