Agent Control
Artifical Intelligence is traditionally associated with controlling agents, such as robots. On the one hand, my research has introduced novel evolutionary methods for robot control (e.g. to ambulate or solve a maze). On the other hand, my work includes gameplaying agents that play games to win or to express idiosynchratic desires.
Large Language Models and Games: A Survey and Roadmap
Roberto Gallotta, Graham Todd, Marvin Zammit, Sam Earle, Antonios Liapis, Julian Togelius, Georgios N. Yannakakis
A large language model (LLM) can operate within the game as a player or as a non-player character, as a player assistant, as a Game Master, or controlling a mechanic of the game. Outside of the game's runtime, an LLM can act as a designer (replacing or assisting a human designer) or as analyst of players' data. Here, we see an example of an automated LLM designer producing card battle setups in CrawLLM.
Abstract: Recent years have seen an explosive increase in research on large language models (LLMs), and accompanying public engagement on the topic. While starting as a niche area within natural language processing, LLMs have shown remarkable potential across a broad range of applications and domains, including games. This paper surveys the current state of the art across the various applications of LLMs in and for games, and identifies the different roles LLMs can take within a game. Importantly, we discuss underexplored areas and promising directions for future uses of LLMs in games and we reconcile the potential and limitations of LLMs within the games domain. As the first comprehensive survey and roadmap at the intersection of LLMs and games, we are hopeful that this paper will serve as the basis for groundbreaking research and innovation in this exciting new field.
in IEEE Transactions on Games, 2024 (Early Access). BibTex
Affectively Framework: Towards Human-like Affect-Based Agents
Matthew Barthet, Roberto Gallotta, Ahmed Khalifa, Antonios Liapis, Georgios N. Yannakakis
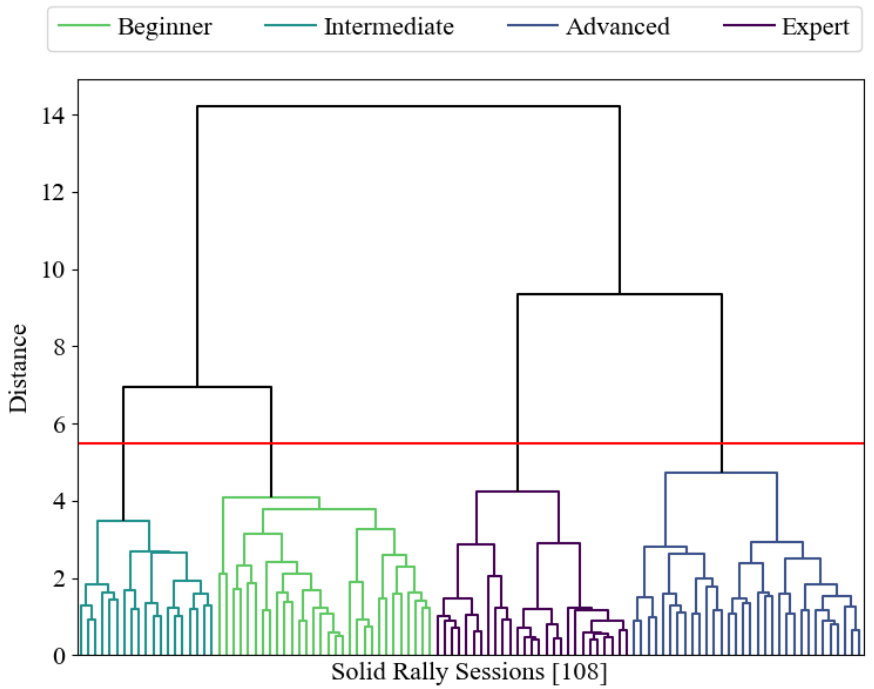
A visualization of the observation state for Solid Rally, one of the three game environments included in the Affectively Framework.
Abstract: Game environments offer a unique opportunity for training virtual agents due to their interactive nature, which provides diverse play traces and affect labels. Despite their potential, no reinforcement learning framework incorporates human affect models as part of their observation space or reward mechanism. To address this, we present the Affectively Framework, a set of Open-AI Gym environments that integrate affect as part of the observation space. This paper introduces the framework and its three game environments and provides baseline experiments to validate its effectiveness and potential.
in Proceedings of the International Conference on Affective Computing and Intelligent Interaction Workshops and Demos, 2024. BibTex
Dungeons & Replicants II: Automated Game Balancing Across Multiple Difficulty Dimensions via Deep Player Behavior Modeling
Johannes Pfau, Antonios Liapis, Georgios N. Yannakakis and Rainer Malaka
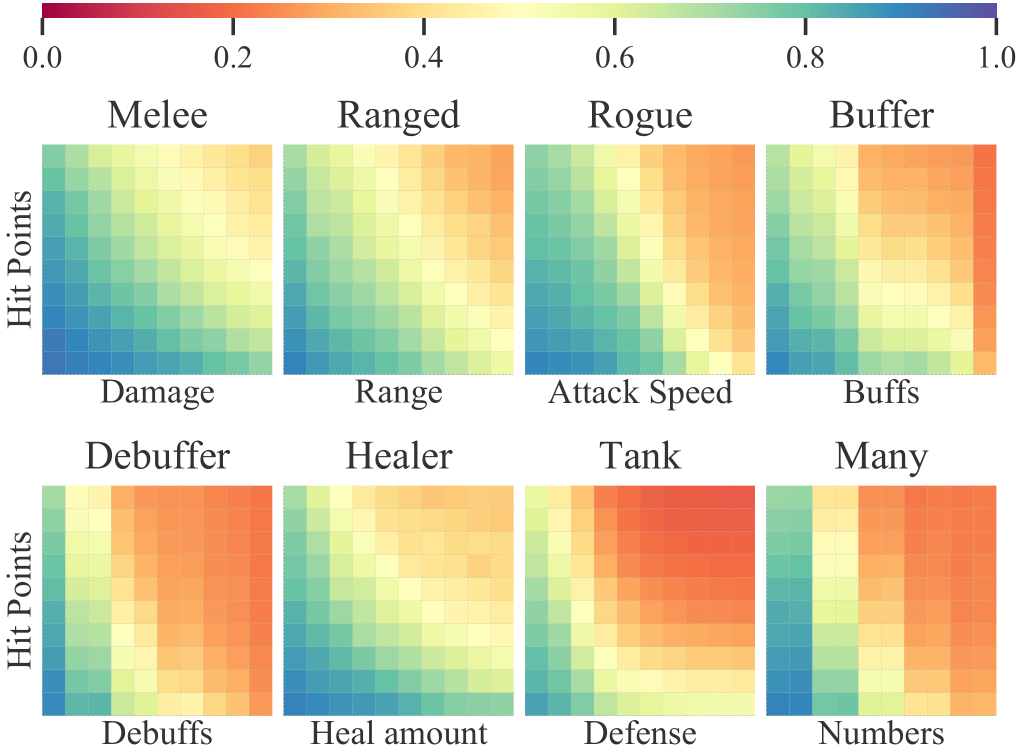
Heatmap of proficiency scores for each encounter across primary and secondary difficulty parameter setups, averaged over all replicants.
Abstract: Video game testing has become a major investment of time, labor and expense in the game industry. Particularly the balancing of in-game units, characters and classes can cause long-lasting issues that persist years after a game's launch. While approaches incorporating artificial intelligence have already shown successes in reducing manual effort and enhancing game development processes, most of these draw on heuristic, generalized or optimal behavior routines, while actual low-level decisions from individual players and their resulting playing styles are rarely considered. In this paper, we apply Deep Player Behavior Modeling to turn atomic actions of 213 players from 6 months of single-player instances within the MMORPG Aion into generative models that capture and reproduce particular playing strategies. In a subsequent simulation, the resulting generative agents ("replicants") were tested against common NPC opponent types of MMORPGs that iteratively increased in difficulty, respective to the primary factor that constitutes this enemy type (Melee, Ranged, Rogue, Buffer, Debuffer, Healer, Tank or Group). As a result, imbalances between classes as well as strengths and weaknesses regarding particular combat challenges could be identified and regulated automatically.
in IEEE Transactions on Games 15(2), 2023. BibTex
Play with Emotion: Affect-Driven Reinforcement Learning
Matthew Barthet, Ahmed Khalifa, Antonios Liapis and Georgios N. Yannakakis

The best playthroughs of a trained agent to maximize affect confidence. Spheres indicate the player's position during the first lap, with red and blue spheres indicating high and low predicted arousal respectively.
Abstract: This paper introduces a paradigm shift by viewing the task of affect modeling as a reinforcement learning (RL) process. According to the proposed paradigm, RL agents learn a policy (i.e. affective interaction) by attempting to maximize a set of rewards (i.e. behavioral and affective patterns) via their experience with their environment (i.e. context). Our hypothesis is that RL is an effective paradigm for interweaving affect elicitation and manifestation with behavioral and affective demonstrations. Importantly, our second hypothesis - building on Damasio's somatic marker hypothesis - is that emotion can be the facilitator of decision-making. We test our hypotheses in a racing game by training Go-Blend agents to model human demonstrations of arousal and behavior; Go-Blend is a modified version of the Go-Explore algorithm which has recently showcased supreme performance in hard exploration tasks. We first vary the arousal-based reward function and observe agents that can effectively display a palette of affect and behavioral patterns according to the specified reward. Then we use arousal-based state selection mechanisms in order to bias the strategies that Go-Blend explores. Our findings suggest that Go-Blend not only is an efficient affect modeling paradigm but, more importantly, affect-driven RL improves exploration and yields higher performing agents, validating Damasio's hypothesis in the domain of games.
in Proceedings of the International Conference on Affective Computing and Intelligent Interaction, 2022. BibTex
Generative Personas That Behave and Experience Like Humans
Matthew Barthet, Ahmed Khalifa, Antonios Liapis and Georgios N. Yannakakis
Clustering of aggregated session data, revealing 4 clusters of players with different in-game performance characteristics.
Abstract: Using artificial intelligence (AI) to automatically test a game remains a critical challenge for the development of richer and more complex game worlds and for the advancement of AI at large. One of the most promising methods for achieving that long-standing goal is the use of generative AI agents, namely procedural personas, that attempt to imitate particular playing behaviors which are represented as rules, rewards, or human demonstrations. All research efforts for building those generative agents, however, have focused solely on playing behavior which is arguably a narrow perspective of what a player actually does in a game. Motivated by this gap in the existing state of the art, in this paper we extend the notion of behavioral procedural personas to cater for player experience, thus examining generative agents that can both behave and experience their game as humans would. For that purpose, we employ the Go-Explore reinforcement learning paradigm for training human-like procedural personas, and we test our method on behavior and experience demonstrations of more than 100 players of a racing game. Our findings suggest that the generated agents exhibit distinctive play styles and experience responses of the human personas they were designed to imitate. Importantly, it also appears that experience, which is tied to playing behavior, can be a highly informative driver for better behavioral exploration.
in Proceedings of the Foundations on Digital Games Conference, 2022. BibTex
Go-Blend Behavior and Affect
Matthew Barthet, Antonios Liapis and Georgios N. Yannakakis
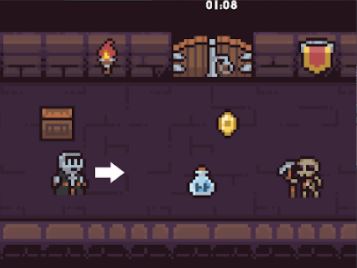
The simple platformer game "Endless Runner" is used as a test case for an agent controller that combines behavioral rewards (playing to win) with affect rewards (playing to experience) based on human users' annotations of arousal during their own playthroughs.
Abstract: This paper proposes a paradigm shift for affective computing by viewing the affect modeling task as a reinforcement learning process. According to our proposed framework the context (environment) and the actions of an agent define the common representation that interweaves behavior and affect. To realise this framework we build on recent advances in reinforcement learning and use a modified version of the Go-Explore algorithm which has showcased supreme performance in hard exploration tasks. In this initial study, we test our framework in an arcade game by training Go-Explore agents to both play optimally and attempt to mimic human demonstrations of arousal. We vary the degree of importance between optimal play and arousal imitation and create agents that can effectively display a palette of affect and behavioral patterns. Our Go-Explore implementation not only introduces a new paradigm for affect modeling; it empowers believable AI-based game testing by providing agents that can blend and express a multitude of behavioral and affective patterns.
in Proceedings of the ACII Workshop on What's Next in Affect Modeling?, 2021. BibTex
Playing Against the Board: Rolling Horizon Evolutionary Algorithms Against Pandemic
Konstantinos Sfikas and Antonios Liapis
Abstract: Competitive board games have provided a rich and diverse testbed for artificial intelligence. This paper contends that collaborative board games pose a different challenge to artificial intelligence as it must balance short-term risk mitigation with long-term winning strategies. Collaborative board games task all players to coordinate their different powers or pool their resources to overcome an escalating challenge posed by the board and a stochastic ruleset. This paper focuses on the exemplary collaborative board game Pandemic and presents a rolling horizon evolutionary algorithm designed specifically for this game. The complex way in which the Pandemic game state changes in a stochastic but predictable way required a number of specially designed forward models, macro-action representations for decision-making, and repair functions for the genetic operations of the evolutionary algorithm. Variants of the algorithm which explore optimistic versus pessimistic game state evaluations, different mutation rates and event horizons are compared against a baseline hierarchical policy agent. Results show that an evolutionary approach via short-horizon rollouts can better account for the future dangers that the board may introduce, and guard against them. Results highlight the types of challenges that collaborative board games pose to artificial intelligence, especially for handling multi-player collaboration interactions.
in IEEE Transactions on Games 14(3), 2021. BibTex
Collaborative Agent Gameplay in the Pandemic Board Game
Konstantinos Sfikas and Antonios Liapis
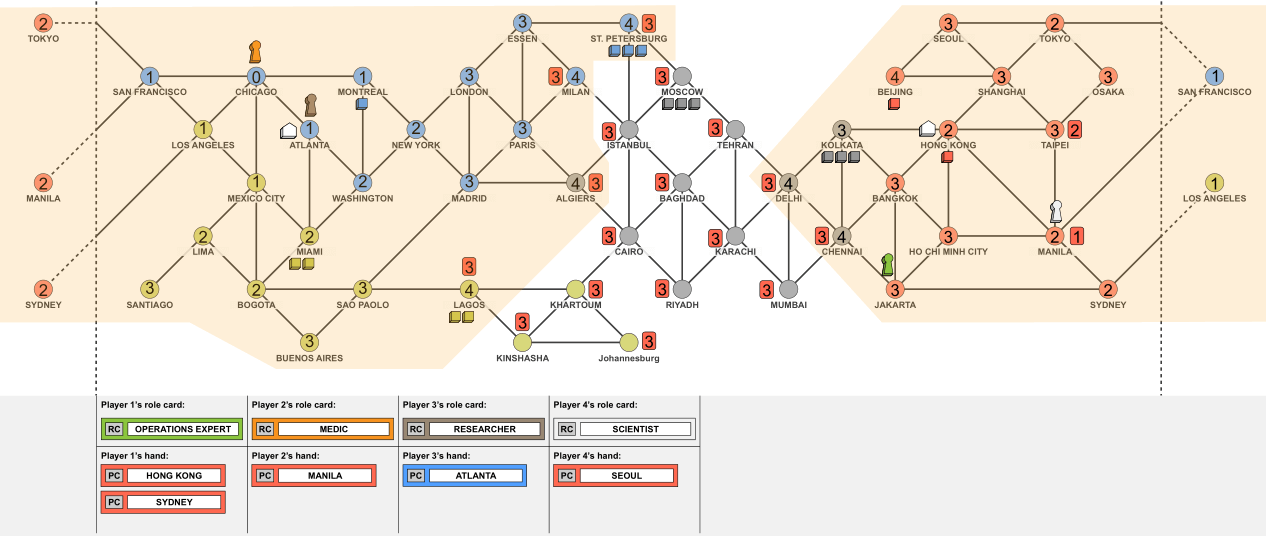
Examples of areas that can be visited by the 2nd player (P2) in a Pandemic game, based on the macro-action structure designed for this AI agent. P2 can move without spending a card to the orange higlighted areas, spending a number of actions shown inside each city. P2 can take a shuttle flight from Atlanta to Hong Kong (both have research stations), increasing reach. P2 can spend the Manila card to travel faster to Manila and Taipei via a direct flight from Chicago. P2 can also travel to Manila via drive/ferry and spend the Manila card there (using the charter flight) to travel anywhere in the word. All cities accessible by spending the red Manila card are shown next to the city with the least actions spent inside a red rectangle.
Abstract: While artificial intelligence has been applied to control players' decisions in board games for over half a century, little attention is given to games with no player competition. Pandemic is an exemplar collaborative board game where all players coordinate to overcome challenges posed by events occurring during the game's progression. This paper proposes an artificial agent which controls all players' actions and balances chances of winning versus risk of losing in this highly stochastic environment. The agent applies a Rolling Horizon Evolutionary Algorithm on an abstraction of the game-state that lowers the branching factor and simulates the game's stochasticity. Results show that the proposed algorithm can find winning strategies more consistently in different games of varying difficulty. The impact of a number of state evaluation metrics is explored, balancing between optimistic strategies that favor winning and pessimistic strategies that guard against losing.
in Proceedings of the Foundations of Digital Games Conference, 2020. BibTex
Dungeons & Replicants: Automated Game Balancing via Deep Player Behavior Modeling
Johannes Pfau, Antonios Liapis, Georg Volkmar, Georgios N. Yannakakis and Rainer Malaka

In-game screenshot of the PvE benchmark in Aion, where player replicas encounter 100 heuristic opponents with increasing difficulty in one-on-one situations (attack horizontally, maxHP vertically).
Abstract: Balancing the options available to players in a way that ensures rich variety and viability is a vital factor for the success of any video game, and particularly competitive multiplayer games. Traditionally, this balancing act requires extensive periods of expert analysis, play testing and debates. While automated gameplay is able to predict outcomes of parameter changes, current approaches mainly rely on heuristic or optimal strategies to generate agent behavior. In this paper, we demonstrate the use of deep player behavior models to represent a player population (n = 213) of the massively multiplayer online role-playing game Aion, which are used, in turn, to generate individual agent behaviors. Results demonstrate significant balance differences in opposing enemy encounters and show how these can be regulated. Moreover, the analytic methods proposed are applied to identify the balance relationships between classes when fighting against each other, reflecting the original developers' design.
in Proceedings of the IEEE Conference on Games, 2020. BibTex
Blending Notions of Diversity for MAP-Elites
Daniele Gravina, Antonios Liapis and Georgios N. Yannakakis
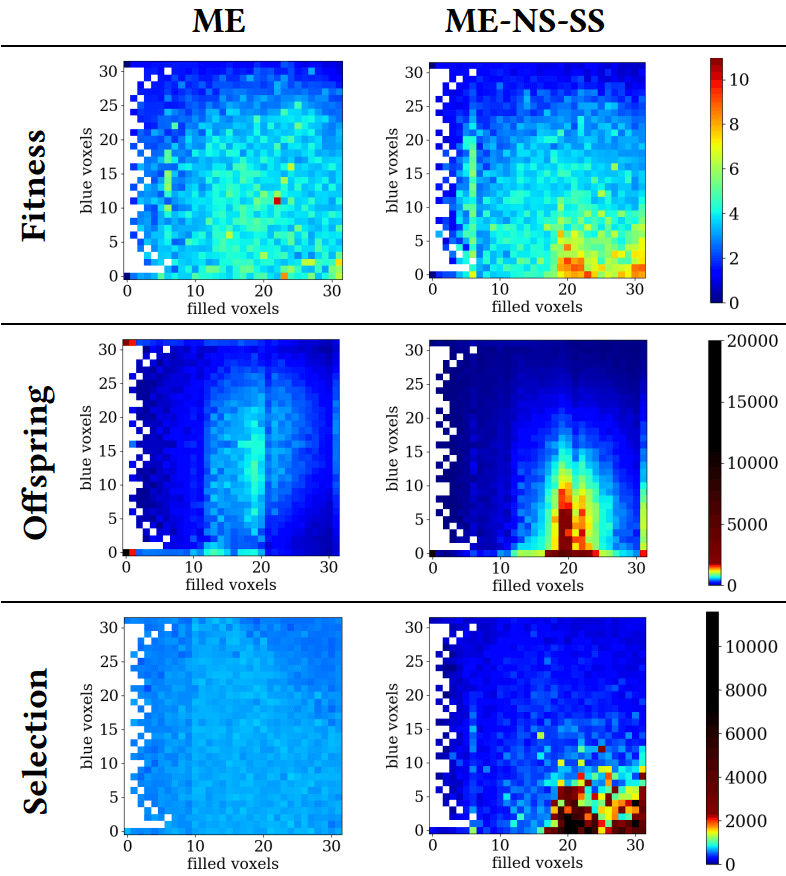
The fitness and feature space of the final MAP-Elites implementation, when using stochastic selection and when using novelty-surprise search based on path divergence.
Abstract: Quality-diversity algorithms focus on discovering multiple diverse and high-performing solutions. MAP-elites is such an algorithm, as it partitions the solution space into bins and searches for the best solution possible for each bin. In this paper, multi-behavior variants of MAP-Elites are tested where the MAP-Elites grid partitions the solution space based on a certain dimension, while selection is guided by measures of diversity on another dimension. Four divergent search algorithms are tested for this selection process, targeting novelty or surprise or their combination, and their performance on a soft robot evolution task is discussed.
in Proceedings of the Genetic and Evolutionary Computation Conference, 2019. BibTex
Quality Diversity Through Surprise
Daniele Gravina, Antonios Liapis and Georgios N. Yannakakis
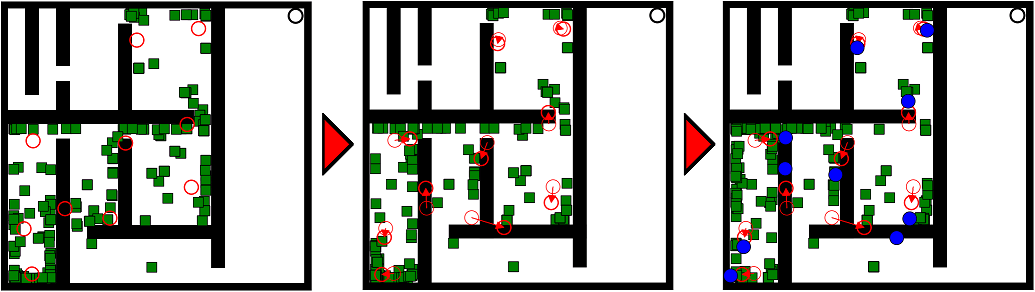
The key phases of the surprise search algorithm in the maze navigation domain, based on 10 behavioral clusters of robot controllers evolved in the two previous generations.
Abstract: Quality diversity is a recent family of evolutionary search algorithms which focus on finding several well-performing (quality) yet different (diversity) solutions with the aim to maintain an appropriate balance between divergence and convergence during search. While quality diversity has already delivered promising results in complex problems, the capacity of divergent search variants for quality diversity remains largely unexplored. Inspired by the notion of surprise as an effective driver of divergent search and its orthogonal nature to novelty this paper investigates the impact of the former to quality diversity performance. For that purpose we introduce three new quality diversity algorithms which employ surprise as a diversity measure, either on its own or combined with novelty, and compare their performance against novelty search with local competition, the state of the art quality diversity algorithm. The algorithms are tested in a robot navigation task across 60 highly deceptive mazes. Our findings suggest that allowing surprise and novelty to operate synergistically for divergence and in combination with local competition leads to quality diversity algorithms of significantly higher efficiency, speed and robustness.
in Transactions on Evolutionary Computation, vol. 23, no 4, pp. 603-616, 2019. BibTex
Fusing Novelty and Surprise for Evolving Robot Morphologies
Daniele Gravina, Antonios Liapis and Georgios N. Yannakakis
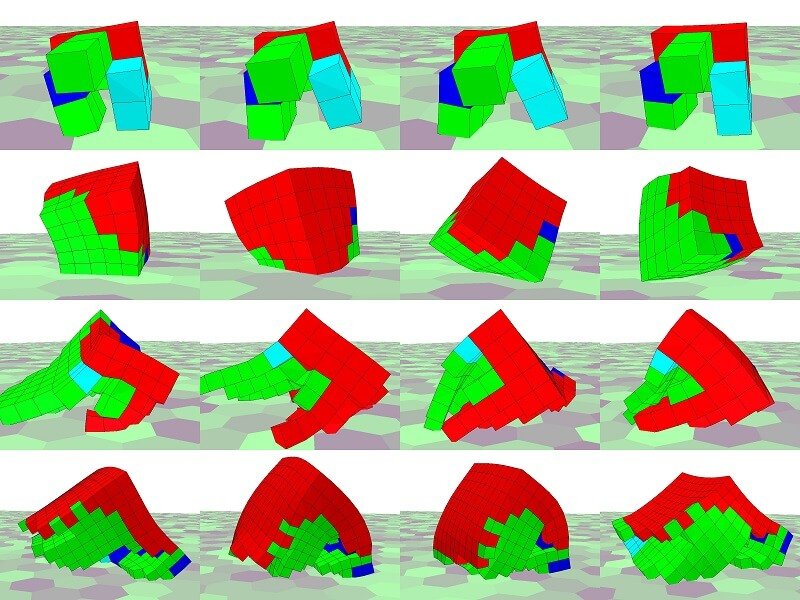
Robot gaits for different lattice resolutions. All robots have been evolved by the novelty-surprise search algorithm.
Abstract: Traditional evolutionary algorithms tend to converge to a single good solution, which can limit their chance of discovering more diverse and creative outcomes. Divergent search, on the other hand, aims to counter convergence to local optima by avoiding selection pressure towards the objective. Forms of divergent search such as novelty or surprise search have proven to be beneficial for both the efficiency and the variety of the solutions obtained in deceptive tasks. Importantly for this paper, early results in maze navigation have shown that combining novelty and surprise search yields an even more effective search strategy due to their orthogonal nature. Motivated by the largely unexplored potential of coupling novelty and surprise as a search strategy, in this paper we investigate how fusing the two can affect the evolution of soft robot morphologies. We test the capacity of the combined search strategy against objective, novelty, and surprise search, by comparing their efficiency and robustness, and the variety of robots they evolve. Our key results demonstrate that novelty-surprise search is generally more efficient and robust across eight different resolutions. Further, surprise search explores the space of robot morphologies more broadly than any other algorithm examined.
in Proceedings of the Genetic and Evolutionary Computation Conference, 2018. BibTex
Automated Playtesting with Procedural Personas through MCTS with Evolved Heuristics
Christoffer Holmgard, Michael Cerny Green, Antonios Liapis and Julian Togelius

Different procedural personas playing through the same MiniDungeons 2 map. From left to right: runner, monster killer, treasure collector, completionist.
Abstract: This paper describes a method for generative player modeling and its application to the automatic testing of game content using archetypal player models called procedural personas. Theoretically grounded in psychological decision theory, procedural personas are implemented using a variation of Monte Carlo Tree Search (MCTS) where the node selection criteria are developed using evolutionary computation, replacing the standard UCB1 criterion of MCTS. Using these personas we demonstrate how generative player models can be applied to a varied corpus of game levels and demonstrate how different play styles can be enacted in each level. In short, we use artificially intelligent personas to construct synthetic playtesters. The proposed approach could be used as a tool for automatic play testing when human feedback is not readily available or when quick visualization of potential interactions is necessary. Possible applications include interactive tools during game development or procedural content generation systems where many evaluations must be conducted within a short time span.
IEEE Transactions on Games, vol. 11, no. 4, pp. 352-362, 2019. BibTex
Coupling Novelty and Surprise for Evolutionary Divergence
Daniele Gravina, Antonios Liapis and Georgios N. Yannakakis

Heatmap of robots' final positions throughout evolution, in the same maze. Robots are evolved towards novelty (left), surprise (middle) and a weighted sum of novelty and surprise (right).
Abstract: Divergent search techniques applied to evolutionary computation, such as novelty search and surprise search, have demonstrated their efficacy in highly deceptive problems compared to traditional objective-based fitness evolutionary processes. While novelty search rewards unseen solutions, surprise search rewards unexpected solutions. As a result these two algorithms perform a different form of search since an expected solution can be novel while an already seen solution can be surprising. As novelty and surprise search have already shown much promise individually, the hypothesis is that an evolutionary process that rewards both novel and surprising solutions will be able to handle deception in a better fashion and lead to more successful solutions faster. In this paper we introduce an algorithm that realises both novelty and surprise search and we compare it against the two algorithms that compose it in a number of robot navigation tasks. The key findings of this paper suggest that coupling novelty and surprise is advantageous compared to each search approach on its own. The introduced algorithm breaks new ground in divergent search as it outperforms both novelty and surprise in terms of efficiency and robustness, and it explores the behavioural space more extensively.
In Proceedings of the Genetic and Evolutionary Computation Conference, 2017. BibTex
Exploring Divergence in Soft Robot Evolution
Daniele Gravina, Antonios Liapis and Georgios N. Yannakakis

Typical soft robot structures evolved through objective-driven search, novelty search, and surprise search.
Abstract: Divergent search is a recent trend in evolutionary computation that does not reward proximity to the objective of the problem it tries to solve. Traditional evolutionary algorithms tend to converge to a single good solution, using a fitness proportional to the quality of the problem's solution, while divergent algorithms aim to counter convergence by avoiding selection pressure towards the ultimate objective. This paper explores how a recent divergent algorithm, surprise search, can affect the evolution of soft robot morphologies, comparing the performance and the structure of the evolved robots.
In Proceedings of the Genetic and Evolutionary Computation Conference, 2017. BibTex
Surprise Search: Beyond Objectives and Novelty
Daniele Gravina, Antonios Liapis and Georgios N. Yannakakis

Heatmaps of final robot locations in mazes solved after 25,000 evaluations by novelty search (left) and surprise search (right). Surprise search results in higher maze exploration.
Abstract: Grounded in the divergent search paradigm and inspired by the principle of surprise for unconventional discovery in computational creativity, this paper introduces surprise search as a new method of evolutionary divergent search. Surprise search is tested in two robot navigation tasks and compared against objective-based evolutionary search and novelty search. The key findings of this paper reveal that surprise search is advantageous compared to the other two search processes. It outperforms objective search and it is as efficient as novelty search in both tasks examined. Most importantly, surprise search is, on average, faster and more robust in solving the navigation problem compared to objective and novelty search. Our analysis reveals that surprise search explores the behavioral space more extensively and yields higher population diversity compared to novelty search.
in Proceedings of the Genetic and Evolutionary Computation Conference. ACM, 2016. BibTex
Monte-Carlo Tree Search for Persona Based Player Modeling
Christoffer Holmgard, Antonios Liapis, Julian Togelius and Georgios N. Yannakakis

Playtraces of procedural personas using MCTS, in different test-bed levels of MiniDungeons 2. To the left is a baseline or 'exit' persona (rewarded only for reaching the exit) and to the right is a monster killer persona (rewarded for each monster kill and to a lesser extent for reaching the exit).
Abstract: Is it possible to conduct player modeling without any players? In this paper we use Monte-Carlo Tree Search-controlled procedural personas to simulate a range of decision making styles in the puzzle game MiniDungeons 2. The purpose is to provide a method for synthetic play testing of game levels with synthetic players based on designer intuition and experience. five personas are constructed, representing five different decision making styles archetypal for the game. The personas vary solely in the weights of decision-making utilities that describe their valuation of a set affordances in MiniDungeons 2. By configuring these weights using designer expert knowledge, and passing the configurations directly to the MCTS algorithm, we make the personas exhibit a number of distinct decision making and play styles.
in Proceedings of the AIIDE workshop on Player Modeling, 2015. BibTex
Evolving Models of Player Decision Making: Personas versus Clones
Christoffer Holmgard, Antonios Liapis, Julian Togelius and Georgios N. Yannakakis

From left to right: the playtraces of a player, a treasure collector procedural persona, and two artificial clone variants of that specific player.
Abstract: The current paper investigates multiple approaches to modeling human decision making styles for procedural play-testing. Building on decision and persona theory we evolve game playing agents representing human decision making styles. Three kinds of agents are evolved from the same representation: procedural personas, evolved from game designer expert knowledge, clones, evolved from observations of human play and aimed at general behavioral replication, and specialized agents, also evolved from observation, but aimed at determining the maximal behavioral replication ability of the representation. These three methods are then compared on their ability to represent individual human decision makers. Comparisons are conducted using three different proposed metrics that address the problem of matching decisions at the action, tactical, and strategic levels. Results indicate that a small gallery of personas evolved from designer intuitions can capture human decision making styles equally well as clones evolved from human play-traces for the testbed game MiniDungeons.
Entertainment Computing. Elsevier Volume 16, 2016, pp. 95–104. BibTex
Personas versus Clones for Player Decision Modeling
Christoffer Holmgard, Antonios Liapis, Julian Togelius and Georgios N. Yannakakis
Abstract: The current paper investigates how to model human play styles. Building on decision and persona theory we evolve game playing agents representing human decision making styles. Two methods are developed, applied, and compared: procedural personas, based on utilities designed with expert knowledge, and clones, trained to reproduce playtraces. Additionally, two metrics for comparing agent and human decision making styles are proposed and compared. Results indicate that personas evolved from designer intuitions can capture human decision making styles equally well as clones evolved from human playtraces.
in Proceedings of the International Conference on Entertainment Computing (ICEC), 2014. BibTex
Generative Agents for Player Decision Modeling in Games
Christoffer Holmgard, Antonios Liapis, Julian Togelius and Georgios N. Yannakakis
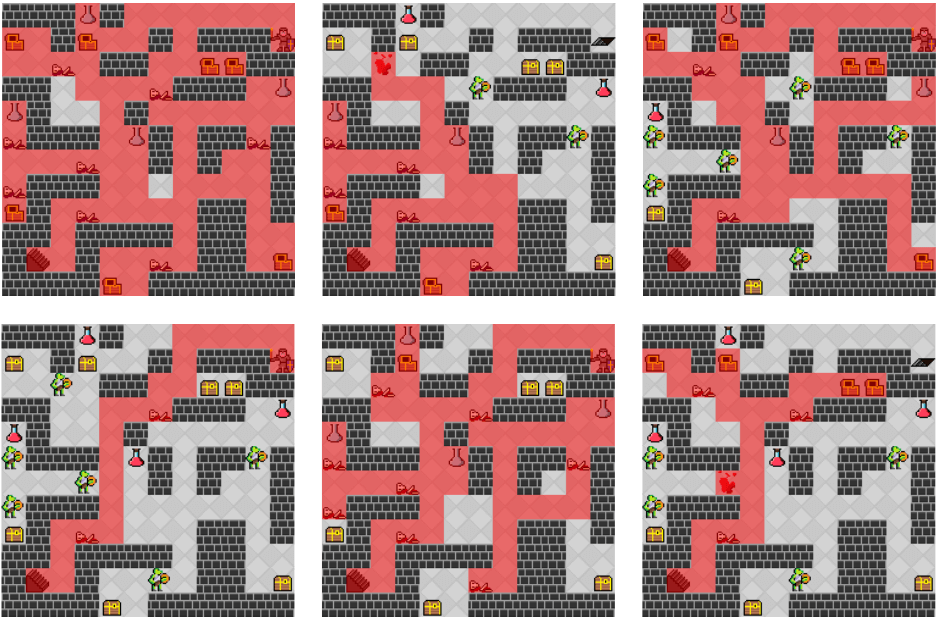
Different human playtraces when playing MiniDungeons (top row) and playtraces of reinforcement-learned agents (bottom row) representing a runner, a monster killer and a treasure collector persona (from left to right).
Abstract: This paper presents a method for modeling player decision making through the use of agents as AI-driven personas. The paper argues that artificial agents, as generative player models, have properties that allow them to be used as psychometrically valid, abstract simulations of a human player's internal decision making processes. Such agents can then be used to interpret human decision making, as personas and playtesting tools in the game design process, as baselines for adapting agents to mimic classes of human players, or as believable, human-like opponents. This argument is explored in a crowdsourced decision making experiment, in which the decisions of human players are recorded in a small-scale dungeon themed puzzle game. Human decisions are compared to the decisions of a number of a priori defined "archetypical" agent-personas, and the humans are characterized by their likeness to or divergence from these. Essentially, at each step the action of the human is compared to what actions a number of reinforcement-learned agents would have taken in the same situation, where each agent is trained using a different reward scheme. finally, extensions are outlined for adapting the agents to represent sub-classes found in the human decision making traces.
in Poster Proceedings of the 9th Conference on the Foundations of Digital Games, 2014. BibTex